文章詳情頁
python - 使用scrapy框架爬百度圖片被墻
瀏覽:113日期:2022-06-30 14:19:37
問題描述
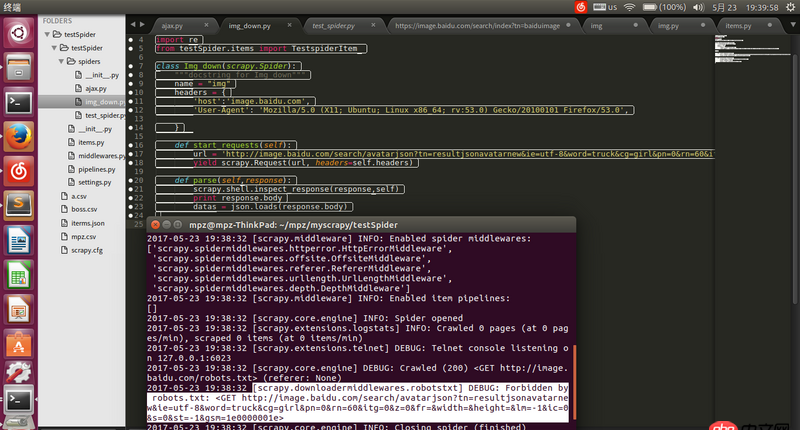
請求地址url是通過firefox查看得到的json的地址,用瀏覽器可以打開,但是用scrapy爬的時候就被ban了求解決辦法。
https://image.baidu.com/searc...
問題解答
回答1:在 settings.py 將 ROBOTSTXT_OBEY = False 試試。
回答2:不要加hearders試試
回答3:贊成樓上,如果還會被墻。可采用scrapy+selenium+phantomjs的方式。
相關文章:
1. angular.js - 輸入郵箱地址之后, 如何使其自動在末尾添加分號?2. 管理員信息修改時的密碼問題3. javascript - JS 里面的 delete object.key 到底刪除了什么?4. android - RxJava 中有根據條件執行不同函數的操作符嗎?5. mysql - 電商如何存儲營業額數據6. javascript - 后臺管理系統左側折疊導航欄數據較多,怎么樣直接通過搜索去定位到具體某一個菜單項位置,并展開當前菜單7. javascript - html5的data屬性怎么指定一個function函數呢?8. javascript - 如何使用nodejs 將.html 文件轉化成canvas9. html5 - 為什么使使用vue cli 腳手架,post-css 沒有自動對css3屬性自動添加瀏覽器前綴呢?10. java如何生成token?
排行榜

 網公網安備
網公網安備