文章詳情頁(yè)
python - 基于scrapy-redis的分布式爬蟲運(yùn)行的時(shí)候不能正常運(yùn)行 遇到的問(wèn)題如下截圖所示
瀏覽:141日期:2022-08-03 11:20:00
問(wèn)題描述

爬蟲運(yùn)行時(shí)一直是這樣的每一分鐘出現(xiàn)一條這樣的信息,無(wú)限循環(huán)。不能爬取下來(lái)數(shù)據(jù)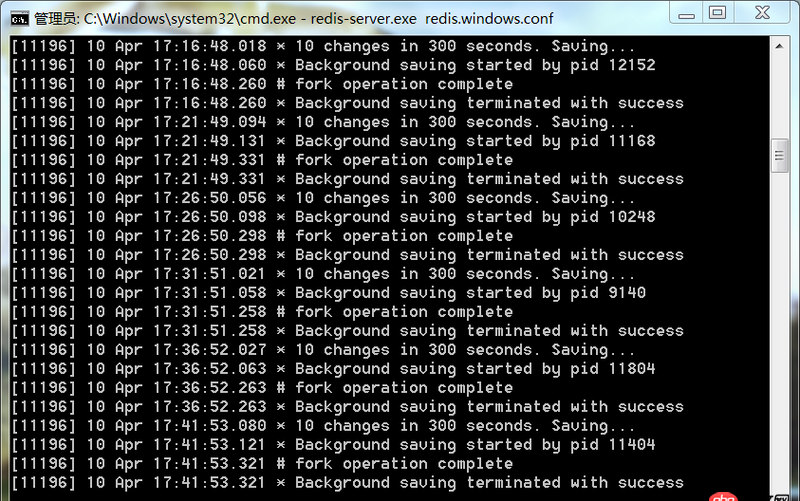
這是redis服務(wù)端的顯示
這樣是什么問(wèn)題,望有高手可以為我解惑,謝謝。
問(wèn)題解答
回答1:使用scrapy_redis,你要去投放url讓spider去爬取,你投放了嗎?比如
redis-cli lpush myspider:start_urls http://google.com
上一條:python3.x - python中的虛擬環(huán)境怎樣設(shè)置一直處于激活狀態(tài)下一條:python - scrapy-redis爬蟲運(yùn)行是連接redis數(shù)據(jù)庫(kù)連接錯(cuò)誤
相關(guān)文章:
1. angular.js - ionic2 瀏覽器跨域問(wèn)題2. mysql 一個(gè)sql 返回多個(gè)總數(shù)3. android - rxjava merge 返回Object對(duì)象數(shù)據(jù)如何緩存4. docker-compose中volumes的問(wèn)題5. 如何用筆記本上的apache做微信開(kāi)發(fā)的服務(wù)器6. CSS3 畫如下圖形7. javascript - 螞蟻金服里的react Modal方法,是怎么把元素插入到頁(yè)面最后的8. python - Scrapy存在內(nèi)存泄漏的問(wèn)題。9. docker 下面創(chuàng)建的IMAGE 他們的 ID 一樣?這個(gè)是怎么回事????10. java - 三位二進(jìn)制表示8進(jìn)制,四位二進(jìn)制表示16進(jìn)制,那么多少二進(jìn)制表示10進(jìn)制呢?
排行榜
熱門標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備