文章詳情頁
python - 標簽樹的下行遍歷如何跳過第一個標簽
瀏覽:132日期:2022-08-08 11:07:17
問題描述
爬取網頁用下行遍歷的找出了我要的標簽,但第一個的內容我是不要的用.children好像無法跳出第一個標簽
for tr in soup.find(id='endText').children: if tr.string is not None:a = tr.string
網頁的內容:
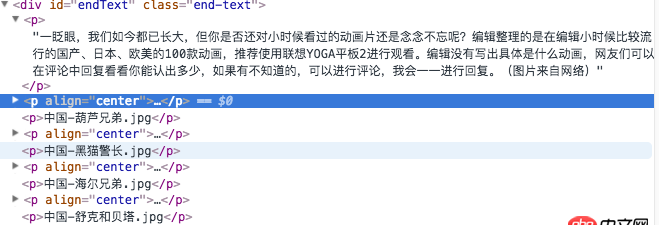 原鏈接:http://digi.163.com/14/1115/0...
原鏈接:http://digi.163.com/14/1115/0...
問題解答
回答1:p_list = list(soup.find(id='endText').find_all(’p’))for p in p_list[1:]: text = p.get_text() img = p.find('img') if img:print img.get(’src’) if text:print text
相關文章:
1. 如何解決docker宿主機無法訪問容器中的服務?2. javascript - 如何使用nodejs 將.html 文件轉化成canvas3. angular.js - 輸入郵箱地址之后, 如何使其自動在末尾添加分號?4. 在mac下出現了兩個docker環境5. javascript - 后臺管理系統左側折疊導航欄數據較多,怎么樣直接通過搜索去定位到具體某一個菜單項位置,并展開當前菜單6. docker-compose中volumes的問題7. python - Scrapy存在內存泄漏的問題。8. java如何生成token?9. angular.js - $stateChangeSuccess事件在狀態跳轉的時候不執行?10. python - 啟動Eric6時報錯:’qscintilla_zh_CN’ could not be loaded
排行榜
 網公網安備
網公網安備