文章詳情頁
網頁爬蟲 - Python爬蟲返回狀態碼與實際情況不符?
瀏覽:225日期:2022-09-03 18:57:11
問題描述
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個爬蟲,輸出狀態碼是200。
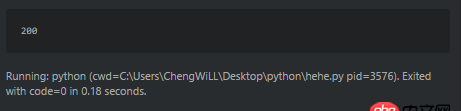
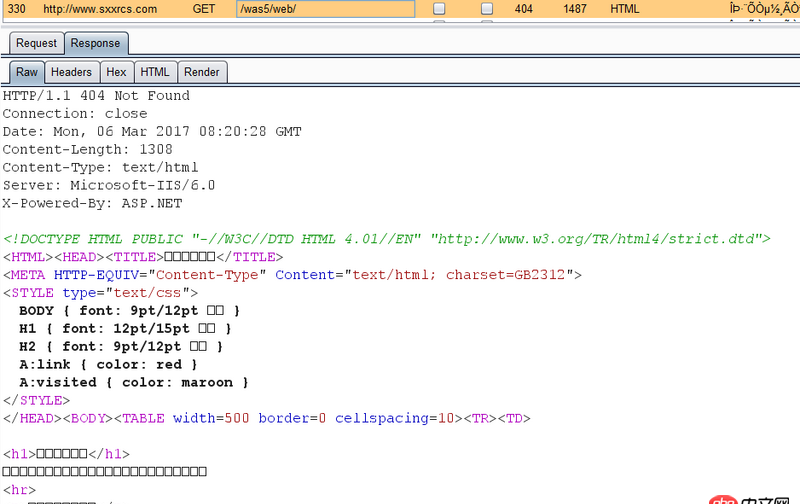
可是直接訪問http://www.sxxrcs.com/was5/web/是404,抓包響應的也是404,請問這是為什么?
問題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關文章:
1. mysql - 記得以前在哪里看過一個估算時間的網站2. python中merge后文件莫名變得非常大3. 希望講講異常處理4. css3 - 純css實現點擊特效5. docker start -a dockername 老是卡住,什么情況?6. javascript - 關于<a>元素與<input>元素的JS事件運行問題7. java - 為什么第一個線程已經釋放了鎖,第二個線程卻不行?8. css3 - [CSS] 動畫效果 3D翻轉bug9. javascript - 如何將一個div始終固定在某個位置;無論屏幕和分辨率怎么變化;div位置始終不變10. 大家好,我想請問一下怎么做搜索欄能夠搜索到自己網站的內容。
排行榜

 網公網安備
網公網安備