python爬蟲(chóng)調(diào)度器用法及實(shí)例代碼
我們一般使用爬蟲(chóng)看到的都是最后的數(shù)據(jù)結(jié)果,對(duì)于整個(gè)的獲取過(guò)程沒(méi)有過(guò)多了解過(guò)。對(duì)于初學(xué)python的小伙伴們來(lái)說(shuō),不光是代碼的練習(xí),還是原理的分析都是必不可少的。
小編把整個(gè)爬取的過(guò)程分為了幾個(gè)部分,從一開(kāi)始的下載,到數(shù)據(jù)的去重解析,再到整個(gè)爬蟲(chóng)循環(huán)的結(jié)束,以圖片和代碼的雙重形式展現(xiàn)給大家,希望能夠?qū)ε老x(chóng)調(diào)度器有一個(gè)深刻的理解。
我們可以編寫(xiě)幾個(gè)元件,每個(gè)元件完成一項(xiàng)功能,下圖中的藍(lán)底白字就是對(duì)這一流程的抽象:
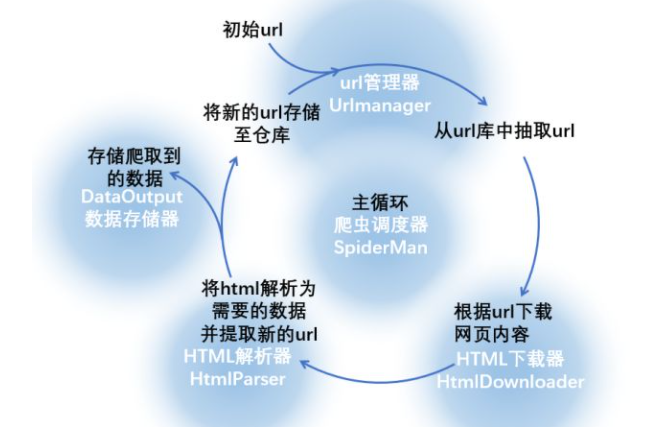
爬蟲(chóng)調(diào)度器將要完成整個(gè)循環(huán),下面寫(xiě)出python下爬蟲(chóng)調(diào)度器的程序:
# coding: utf-8new_urls = set()data = {}class SpiderMan(object): def __init__(self): #調(diào)度器內(nèi)包含其它四個(gè)元件,在初始化調(diào)度器的時(shí)候也要建立四個(gè)元件對(duì)象的實(shí)例 self.manager = UrlManager() self.downloader = HtmlDownloader() self.parser = HtmlParser() self.output = DataOutput() def spider(self, origin_url): #添加初始url self.manager.add_new_url(origin_url) #下面進(jìn)入主循環(huán),暫定爬取頁(yè)面總數(shù)小于100 num = 0 while(self.manager.has_new_url() and self.manager.old_url_size()<100): try: num = num + 1 print '正在處理第{}個(gè)鏈接'.format(num) #從新url倉(cāng)庫(kù)中獲取url new_url = self.manager.get_new_url() #調(diào)用html下載器下載頁(yè)面 html = self.downloader.download(new_url) #調(diào)用解析器解析頁(yè)面,返回新的url和data try: new_urls, data = self.parser.parser(new_url, html) except Exception, e: print e for url in new_urls: self.manager.add_new_url(url) #將已經(jīng)爬取過(guò)的這個(gè)url添加至老url倉(cāng)庫(kù)中 self.manager.add_old_url(new_url) #將返回的數(shù)據(jù)存儲(chǔ)至文件 self.output.store_data(data) print 'store data succefully' print '第{}個(gè)鏈接已經(jīng)抓取完成'.format(self.manager.old_url_size()) except Exception, e: print e #爬取循環(huán)結(jié)束的時(shí)候?qū)⒋鎯?chǔ)的數(shù)據(jù)輸出至文件 self.output.output_html()
從整個(gè)循環(huán)的流程我們可以看出,由爬蟲(chóng)調(diào)度器指揮四個(gè)元件完成數(shù)據(jù)的抓取、篩選、保存流程,并以此為基礎(chǔ)還可以進(jìn)行新的循環(huán)。看懂原理之后,我們就可以使用以上的代碼進(jìn)行實(shí)戰(zhàn)啦。
到此這篇關(guān)于python爬蟲(chóng)調(diào)度器用法及實(shí)例代碼的文章就介紹到這了,更多相關(guān)python爬蟲(chóng)調(diào)度器是什么內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. XML入門(mén)的常見(jiàn)問(wèn)題(二)2. CSS可以做的幾個(gè)令你嘆為觀止的實(shí)例分享3. 低版本IE正常運(yùn)行HTML5+CSS3網(wǎng)站的3種解決方案4. 概述IE和SQL2k開(kāi)發(fā)一個(gè)XML聊天程序5. XML入門(mén)精解之結(jié)構(gòu)與語(yǔ)法6. 詳解瀏覽器的緩存機(jī)制7. 小技巧處理div內(nèi)容溢出8. 詳解CSS偽元素的妙用單標(biāo)簽之美9. XHTML 1.0:標(biāo)記新的開(kāi)端10. HTML5 Canvas繪制圖形從入門(mén)到精通

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備