python 識別登錄驗證碼圖片功能的實現代碼(完整代碼)
在編寫自動化測試用例的時候,每次登錄都需要輸入驗證碼,后來想把讓python自己識別圖片里的驗證碼,不需要自己手動登陸,所以查了一下識別功能怎么實現,做一下筆記。
首選導入一些用到的庫,re、Image、pytesseract、selenium、time
import re # 用于正則from PIL import Image # 用于打開圖片和對圖片處理import pytesseract # 用于圖片轉文字from selenium import webdriver # 用于打開網站import time # 代碼運行停頓
首先需要獲取驗證碼圖片,才能進一步識別。
創建類,定義webdriver和find_element_by_selector方法,用來打開網頁和定位驗證碼圖片的元素
class VerificationCode: def __init__(self): self.driver = webdriver.Firefox() self.find_element = self.driver.find_element_by_css_selector
然后打開瀏覽器截取驗證碼圖片
def get_pictures(self): self.driver.get(’http://123.255.123.3’) # 打開登陸頁面 self.driver.save_screenshot(’pictures.png’) # 全屏截圖 page_snap_obj = Image.open(’pictures.png’) img = self.find_element(’#pic’) # 驗證碼元素位置 time.sleep(1) location = img.location size = img.size # 獲取驗證碼的大小參數 left = location[’x’] top = location[’y’] right = left + size[’width’] bottom = top + size[’height’] image_obj = page_snap_obj.crop((left, top, right, bottom)) # 按照驗證碼的長寬,切割驗證碼 image_obj.show() # 打開切割后的完整驗證碼 self.driver.close() # 處理完驗證碼后關閉瀏覽器 return image_obj
未處理前的驗證碼圖片如下:
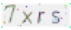
未處理的驗證碼圖片,對于python來說識別率較低,仔細看可以發現圖片里有很對五顏六色擾亂識別的點,非常影響識別率。
下面對獲取的驗證碼進行處理。
首先用convert把圖片轉成黑白色。設置threshold閾值,超過閾值的為黑色
def processing_image(self): image_obj = self.get_pictures() # 獲取驗證碼 img = image_obj.convert('L') # 轉灰度 pixdata = img.load() w, h = img.size threshold = 160 # 該閾值不適合所有驗證碼,具體閾值請根據驗證碼情況設置 # 遍歷所有像素,大于閾值的為黑色 for y in range(h): for x in range(w):if pixdata[x, y] < threshold: pixdata[x, y] = 0else: pixdata[x, y] = 255 return img
經過灰度處理后的圖片
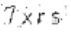
然后刪除一些擾亂識別的像素點。
def delete_spot(self): images = self.processing_image() data = images.getdata() w, h = images.size black_point = 0 for x in range(1, w - 1): for y in range(1, h - 1):mid_pixel = data[w * y + x] # 中央像素點像素值if mid_pixel < 50: # 找出上下左右四個方向像素點像素值 top_pixel = data[w * (y - 1) + x] left_pixel = data[w * y + (x - 1)] down_pixel = data[w * (y + 1) + x] right_pixel = data[w * y + (x + 1)] # 判斷上下左右的黑色像素點總個數 if top_pixel < 10: black_point += 1 if left_pixel < 10: black_point += 1 if down_pixel < 10: black_point += 1 if right_pixel < 10: black_point += 1 if black_point < 1: images.putpixel((x, y), 255) black_point = 0 # images.show() return images
經過去除噪點處理后的圖片
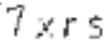
最后把處理后的圖片轉成文字。
先設置pytesseract的路徑,因為默認路徑是錯的,然后轉換圖片為文字,由于個別圖片中識別會出現處理遺漏,會被識別成空格或則點或則分號什么的,所以增加了一個去除驗證碼中特殊字符的處理。
PS:tesseract文件下載鏈接
def image_str(self): image = self.delete_spot() pytesseract.pytesseract.tesseract_cmd = r'C:Program FilesTesseract-OCRtesseract.exe' # 設置pyteseract路徑 result = pytesseract.image_to_string(image) # 圖片轉文字 resultj = re.sub(u'([^u4e00-u9fa5u0030-u0039u0041-u005au0061-u007a])', '', result) # 去除識別出來的特殊字符 result_four = resultj[0:4] # 只獲取前4個字符 # print(resultj) # 打印識別的驗證碼 return result_four
完整代碼如下:
import re # 用于正則from PIL import Image # 用于打開圖片和對圖片處理import pytesseract # 用于圖片轉文字from selenium import webdriver # 用于打開網站import time # 代碼運行停頓 class VerificationCode: def __init__(self): self.driver = webdriver.Firefox() self.find_element = self.driver.find_element_by_css_selector def get_pictures(self): self.driver.get(’http://123.255.123.3’) # 打開登陸頁面 self.driver.save_screenshot(’pictures.png’) # 全屏截圖 page_snap_obj = Image.open(’pictures.png’) img = self.find_element(’#pic’) # 驗證碼元素位置 time.sleep(1) location = img.location size = img.size # 獲取驗證碼的大小參數 left = location[’x’] top = location[’y’] right = left + size[’width’] bottom = top + size[’height’] image_obj = page_snap_obj.crop((left, top, right, bottom)) # 按照驗證碼的長寬,切割驗證碼 image_obj.show() # 打開切割后的完整驗證碼 self.driver.close() # 處理完驗證碼后關閉瀏覽器 return image_obj def processing_image(self): image_obj = self.get_pictures() # 獲取驗證碼 img = image_obj.convert('L') # 轉灰度 pixdata = img.load() w, h = img.size threshold = 160 # 遍歷所有像素,大于閾值的為黑色 for y in range(h): for x in range(w):if pixdata[x, y] < threshold: pixdata[x, y] = 0else: pixdata[x, y] = 255 return img def delete_spot(self): images = self.processing_image() data = images.getdata() w, h = images.size black_point = 0 for x in range(1, w - 1): for y in range(1, h - 1):mid_pixel = data[w * y + x] # 中央像素點像素值if mid_pixel < 50: # 找出上下左右四個方向像素點像素值 top_pixel = data[w * (y - 1) + x] left_pixel = data[w * y + (x - 1)] down_pixel = data[w * (y + 1) + x] right_pixel = data[w * y + (x + 1)] # 判斷上下左右的黑色像素點總個數 if top_pixel < 10: black_point += 1 if left_pixel < 10: black_point += 1 if down_pixel < 10: black_point += 1 if right_pixel < 10: black_point += 1 if black_point < 1: images.putpixel((x, y), 255) black_point = 0 # images.show() return images def image_str(self): image = self.delete_spot() pytesseract.pytesseract.tesseract_cmd = r'C:Program FilesTesseract-OCRtesseract.exe' # 設置pyteseract路徑 result = pytesseract.image_to_string(image) # 圖片轉文字 resultj = re.sub(u'([^u4e00-u9fa5u0030-u0039u0041-u005au0061-u007a])', '', result) # 去除識別出來的特殊字符 result_four = resultj[0:4] # 只獲取前4個字符 # print(resultj) # 打印識別的驗證碼 return result_four if __name__ == ’__main__’: a = VerificationCode() a.image_str()
看評論有很多人需要tesseract.exe文件,但是由于文件過大,發郵件會出現無法下載的情況,有需要的可以在一下連接里下載tesseract.exe文件
到此這篇關于python 識別登錄驗證碼圖片(完整代碼)的文章就介紹到這了,更多相關python識別登錄驗證碼圖片內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備