詳解用Python爬蟲獲取百度企業信用中企業基本信息
一、背景
希望根據企業名稱查詢其經緯度,所在的省份、城市等信息。直接將企業名稱傳給百度地圖提供的API,得到的經緯度是非常不準確的,因此希望獲取企業完整的地理位置,這樣傳給API后結果會更加準確。百度企業信用提供了企業基本信息查詢的功能。希望通過Python爬蟲獲取企業基本信息。目前已基本實現了這一需求。本文最后會提供具體的代碼。代碼僅供學習參考,希望不要惡意爬取數據!
二、分析
以蘇寧為例。輸入“江蘇蘇寧”后,查詢結果如下:
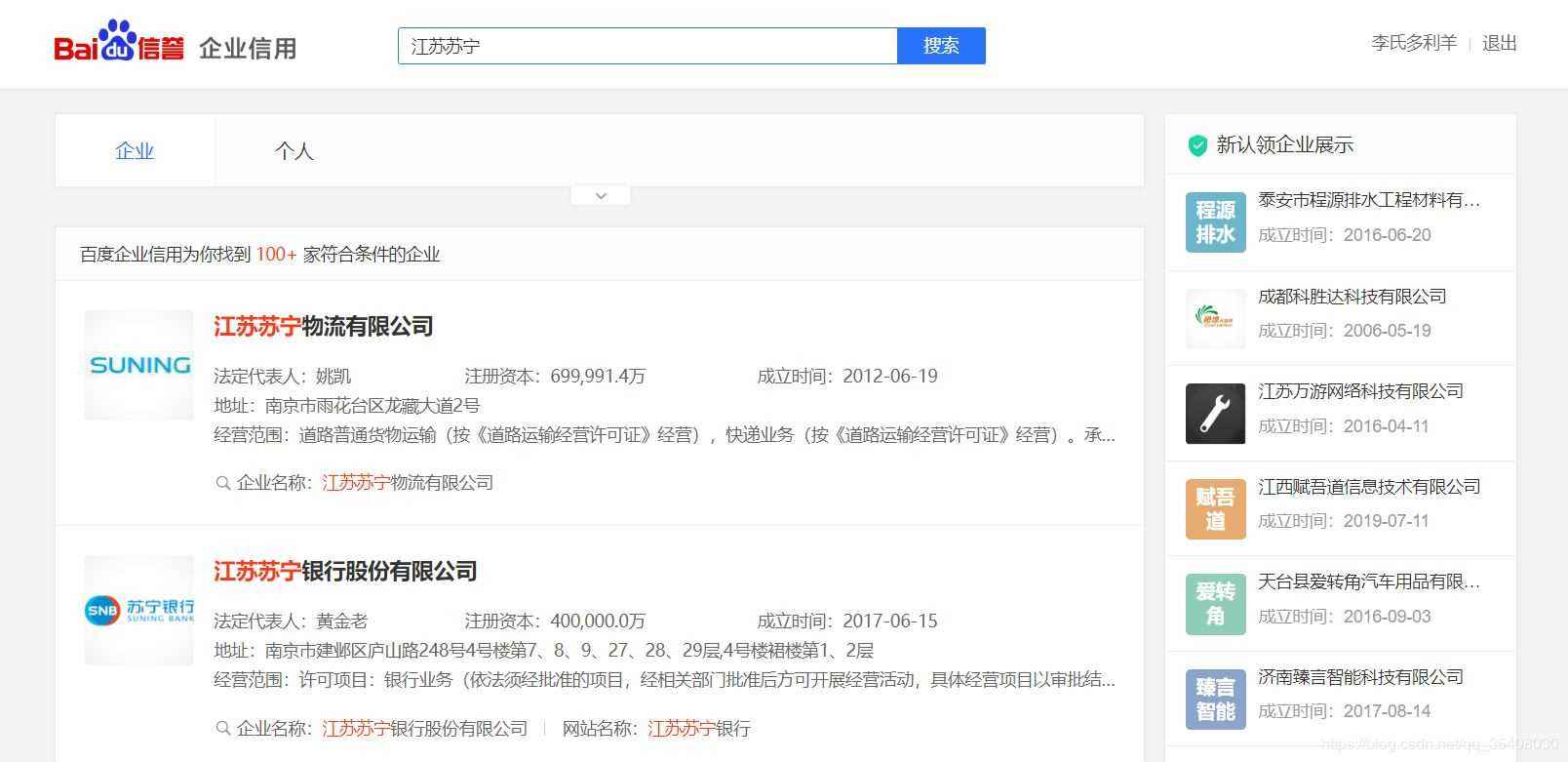
經過分析,這里列示的企業信息是用JavaScript動態生成的。服務器最初傳過來的未經渲染的HTML如下:
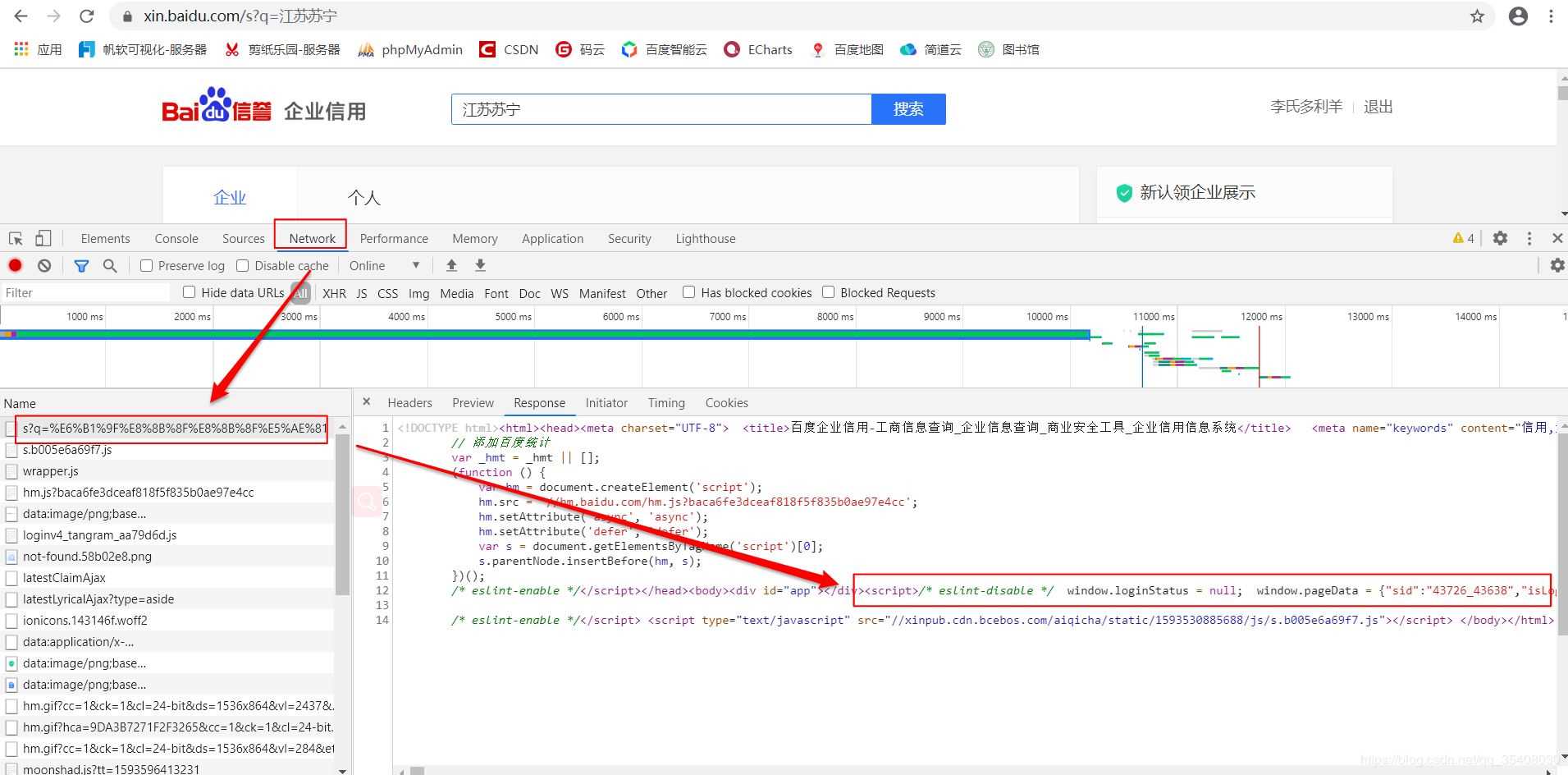
注意其中標注出來的JS代碼。有意思的是,企業基本信息都可以直接從這段JS代碼中獲取,無需構造復雜的參數。

這是進一步查看的結果,注意那個“resultList”,后面存放的就是頁面中的企業信息。顯然,利用正則表達式提取需要的字符串,轉換成JSON就可以了。
三、源碼
以下代碼為查詢某個企業的基本信息提供了API:
#!/usr/bin/env python# -*- coding:utf-8 -*-# @Author: Wild Orange# @Email: jixuanfan_seu@163.com# @Date: 2020-06-19 22:38:14# @Last Modified time: 2020-07-01 17:33:13import requestsimport reimport jsonheaders={’User-Agent’: ’Chrome/76.0.3809.132’}#正則表達式提取數據re_get_js=re.compile(r’<script>([sS]*?)</script>’)re_resultList=re.compile(r’'resultList':([{.+?}]}])’)def Get_company_info(name):’’’@func: 通過百度企業信用查詢企業基本信息’’’url=’https://xin.baidu.com/s?q=%s’%nameres=requests.get(url,headers=headers)if res.status_code==200:html=res.textretVal=_parse_baidu_company_info(html)return retValelse:print(’無法獲取%s的企業信息’%name)def _parse_baidu_company_info(html):’’’@function:解析百度企業信用提供的企業基本信息@output: list of dict, [{},{},...]pid: 跳轉到具體企業頁面的參數bid: 具體企業頁面URL中的參數name: 企業名稱type: 企業類型date: 成立日期address: 地址person: 法人代表status: 存續狀態regCap: 注冊資本scope: 經營范圍’’’js=re_get_js.findall(html)[1]data=re_resultList.search(js)if not data:returncompant_list=json.loads(data.group(1))retVal=[]for x in compant_list:regCap=x[’regCap’].replace(’,’,’’)if regCap[-1]==’萬’:regCap=regCap[:-1]regCap=float(regCap)address=x[’domicile’].replace(’<em>’,’’).replace(’</em>’,’’)temp_v={’pid’:x[’pid’],’bid’:x[’bid’],’name’:x[’titleName’],’type’:x[’entType’],’date’:x[’validityFrom’],’address’:address,’person’:x[’legalPerson’],’status’:x[’openStatus’],’regCap’:regCap,’scope’:x[’scope’]}retVal.append(temp_v)return retVal
四、使用方法
直接將需要查詢的企業名稱傳入Get_company_info:
res=Get_company_info(’江蘇蘇寧’)print(res)
結果:

需要注意的是:
返回的是字典構成的數組,每個字典元素代表一家企業的信息。順序與瀏覽器中顯示的順序相同。字典中參數的含義已在_parse_baidu_company_info函數的注釋中說明。程序僅獲取第一頁的信息。如果要查詢多頁,可以修改源碼。程序僅獲取企業的基本信息,沒有進入企業的具體頁面,如:蘇寧物流具體頁面。不過返回結果中的pid或bid應該能用于構造查詢頁面的URL。
最后再次強調:代碼僅供學習參考,希望不要惡意爬取數據!
到此這篇關于詳解用Python爬蟲獲取百度企業信用中企業基本信息的文章就介紹到這了,更多相關Python爬蟲獲取百度企業信用內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備