python實現密度聚類(模板代碼+sklearn代碼)
本人在此就不搬運書上關于密度聚類的理論知識了,僅僅實現密度聚類的模板代碼和調用skelarn的密度聚類算法。有人好奇,為什么有sklearn庫了還要自己去實現呢?其實,庫的代碼是比自己寫的高效且容易,但自己實現代碼會對自己對算法的理解更上一層樓。
#調用科學計算包與繪圖包import numpy as npimport randomimport matplotlib.pyplot as plt
# 獲取數據def loadDataSet(filename): dataSet=np.loadtxt(filename,dtype=np.float32,delimiter=’,’) return dataSet
#計算兩個向量之間的歐式距離def calDist(X1 , X2 ): sum = 0 for x1 , x2 in zip(X1 , X2): sum += (x1 - x2) ** 2 return sum ** 0.5
#獲取一個點的ε-鄰域(記錄的是索引)def getNeibor(data , dataSet , e): res = [] for i in range(dataSet.shape[0]): if calDist(data , dataSet[i])<e: res.append(i) return res
#密度聚類算法def DBSCAN(dataSet , e , minPts): coreObjs = {}#初始化核心對象集合 C = {} n = dataSet.shape[0] #找出所有核心對象,key是核心對象的index,value是ε-鄰域中對象的index for i in range(n): neibor = getNeibor(dataSet[i] , dataSet , e) if len(neibor)>=minPts: coreObjs[i] = neibor oldCoreObjs = coreObjs.copy() k = 0#初始化聚類簇數 notAccess = list(range(n))#初始化未訪問樣本集合(索引) while len(coreObjs)>0: OldNotAccess = [] OldNotAccess.extend(notAccess) cores = coreObjs.keys() #隨機選取一個核心對象 randNum = random.randint(0,len(cores)-1) cores=list(cores) core = cores[randNum] queue = [] queue.append(core) notAccess.remove(core) while len(queue)>0: q = queue[0] del queue[0] if q in oldCoreObjs.keys() :delte = [val for val in oldCoreObjs[q] if val in notAccess]#Δ = N(q)∩Γqueue.extend(delte)#將Δ中的樣本加入隊列QnotAccess = [val for val in notAccess if val not in delte]#Γ = ΓΔ k += 1 C[k] = [val for val in OldNotAccess if val not in notAccess] for x in C[k]: if x in coreObjs.keys():del coreObjs[x] return C
# 代碼入口dataSet = loadDataSet(r'E:jupytersklearn學習sklearn聚類DataSet.txt')print(dataSet)print(dataSet.shape)C = DBSCAN(dataSet, 0.11, 5)draw(C, dataSet)
結果圖:
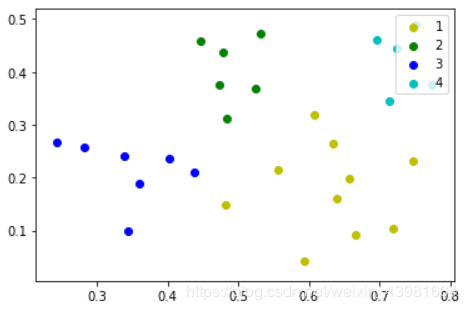
下面是調用sklearn庫的實現
db = skc.DBSCAN(eps=1.5, min_samples=3).fit(dataSet) #DBSCAN聚類方法 還有參數,matric = ''距離計算方法labels = db.labels_ #和X同一個維度,labels對應索引序號的值 為她所在簇的序號。若簇編號為-1,表示為噪聲print(’每個樣本的簇標號:’)print(labels)raito = len(labels[labels[:] == -1]) / len(labels) #計算噪聲點個數占總數的比例print(’噪聲比:’, format(raito, ’.2%’))n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # 獲取分簇的數目print(’分簇的數目: %d’ % n_clusters_)print('輪廓系數: %0.3f' % metrics.silhouette_score(X, labels)) #輪廓系數評價聚類的好壞for i in range(n_clusters_): print(’簇 ’, i, ’的所有樣本:’) one_cluster = X[labels == i] print(one_cluster) plt.plot(one_cluster[:,0],one_cluster[:,1],’o’)plt.show()
到此這篇關于python實現密度聚類(模板代碼+sklearn代碼)的文章就介紹到這了,更多相關python 密度聚類內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備