Python利用PyPDF2庫獲取PDF文件總頁碼實例
Python中可以利用PyPDF2庫來獲取該pdf文件的總頁碼,可以根據(jù)下面的方法一步步進行下去:
1、首先,要安裝PyPDF2庫,利用以下命令即可:
pip install PyPDF2
2、接著,就是直接編寫代碼了,其中我新建了一個py文件,名為file_utils.py,代碼如下:
from PyPDF2 import PdfFileReader def get_num_pages(file_path): ''' 獲取文件總頁碼 :param file_path: 文件路徑 :return: ''' reader = PdfFileReader(file_path) # 不解密可能會報錯:PyPDF2.utils.PdfReadError: File has not been decrypted if reader.isEncrypted: reader.decrypt(’’) page_num = reader.getNumPages() return page_num
3、這樣就可以獲得該pdf文件的總頁數(shù)了,但是需要傳遞文件路徑進去,因為需要讀取這個文件。
4、以上內(nèi)容僅供學(xué)習(xí)參考,謝謝!
補充知識:使用python合并pdf文件帶書簽
1、需求:
將幾本紙質(zhì)書進行了掃描,可是掃描的每頁生成一個pdf文件。需要怎么才能把這些pdf文件合成一個呢?adoba acrobat工具支持,可是收費。我們平時用的都是adoba reader,只有讀pdf的功能沒有合并等高級功能。網(wǎng)上的一些免費工具又擔(dān)心有病毒或綁定程序。
所以考慮看看pyton實現(xiàn)。網(wǎng)上找了下python合并pdf的腳本,發(fā)現(xiàn)也沒有添加書簽的功能的,有添加書簽的也不是很靈活。
所有對網(wǎng)上找的一個python程序進行了升級,可以實現(xiàn)合并pdf并每個章節(jié)加入書簽。
文件準(zhǔn)備:
先將掃描的pdf文件,每一章放到一個文件夾中,文件夾名字用章節(jié)名命名。這樣最終程序就能將章節(jié)名作為書簽了,而不是默認(rèn)將每頁都生成書簽。
2、程序代碼
代碼運行環(huán)境:python3
需要安裝PyPDF2包:pip install PyPDF2
#!/usr/bin/env python3# -*- coding: utf-8 -*-’’’ 本腳本用來合并pdf文件,支持帶一級子目錄的 每章內(nèi)容分別放在不同的目錄下,目錄名為章節(jié)名 最終生成的pdf,按章節(jié)名生成書簽’’’import os, sys, codecsfrom PyPDF2 import PdfFileReader, PdfFileWriter, PdfFileMergerimport globdef getFileName(filepath): ’’’ 獲取當(dāng)前目錄下的所有pdf文件 ’’’ file_list = glob.glob(filepath+'/*.pdf') # 默認(rèn)安裝字典序排序,也可以安裝自定義的方式排序 # file_list.sort() return file_listdef get_dirs(filepath=’’, dirlist_out=[], dirpathlist_out=[]): # 遍歷filepath下的所有目錄 for dir in os.listdir(filepath): dirpathlist_out.append(filepath + ’’ + dir) return dirpathlist_outdef merge_childdir_files(path): ’’’ 每個子目錄下合并生成一個pdf ’’’ dirpathlist = get_dirs(path) if len(dirpathlist) == 0: print('當(dāng)前目錄不存在子目錄') sys.exit() for dir in dirpathlist: mergefiles(dir, dir)def mergefiles(path, output_filename, import_bookmarks=False): # 遍歷目錄下的所有pdf將其合并輸出到一個pdf文件中,輸出的pdf文件默認(rèn)帶書簽,書簽名為之前的文件名 # 默認(rèn)情況下原始文件的書簽不會導(dǎo)入,使用import_bookmarks=True可以將原文件所帶的書簽也導(dǎo)入到輸出的pdf文件中 merger = PdfFileMerger() filelist = getFileName(path) if len(filelist) == 0: print('當(dāng)前目錄及子目錄下不存在pdf文件') sys.exit() for filename in filelist: f = codecs.open(filename, ’rb’) file_rd = PdfFileReader(f) short_filename = os.path.basename(os.path.splitext(filename)[0]) if file_rd.isEncrypted == True: print(’不支持的加密文件:%s’%(filename)) continue merger.append(file_rd, bookmark=short_filename, import_bookmarks=import_bookmarks) print(’合并文件:%s’%(filename)) f.close() # out_filename = os.path.join(os.path.abspath(path), output_filename) merger.write(output_filename + '.pdf') print(’合并后的輸出文件:%s’%(output_filename)) merger.close()if __name__ == '__main__': # 每個章節(jié)一個子目錄,先分別合并每個子目錄文件為一個pdf,然后再將這些pdf合并為一個大的pdf,這樣做目的是想生成每個章節(jié)的書簽 # 1.指定目錄 # 原始pdf所在目錄 path = 'D:spdf' # 輸出pdf路徑和文件名 output_filename = 'D:spdf戰(zhàn)略規(guī)劃 公司實現(xiàn)持續(xù)成功的方法、工具和實踐 羅熙昶 2018-09' # 2.生成子目錄的pdf # merge_childdir_files(path) # 3.子目錄pdf合并為總的pdf mergefiles(path, output_filename)
3、程序使用
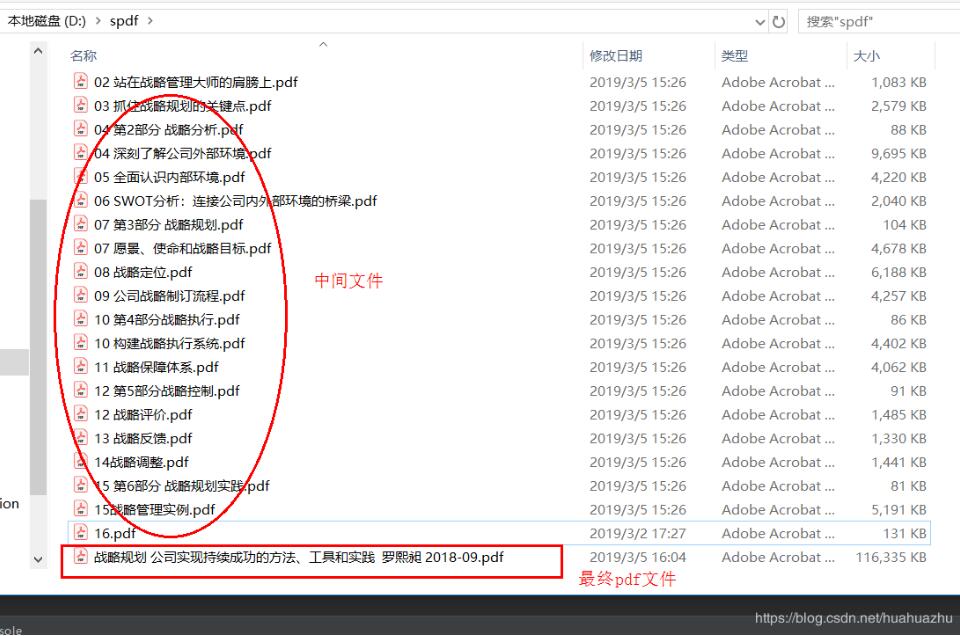
將要生成的pdf文件目錄導(dǎo)入到程序指定目錄下,例如我程序中的path是“D:spdf”,然后指定最終輸出的文件路徑及文件名,我上面的output_filename是'D:spdf戰(zhàn)略規(guī)劃 公司實現(xiàn)持續(xù)成功的方法、工具和實踐 羅熙昶 2018-09'
數(shù)據(jù)結(jié)果如下:
以上這篇Python利用PyPDF2庫獲取PDF文件總頁碼實例就是小編分享給大家的全部內(nèi)容了,希望能給大家一個參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備