使用Python+OpenCV進行卡類型及16位卡號數字的OCR功能
這篇博客將介紹如何通過OpenCV和Python使用模板匹配執行光學字符識別(OCR)。具體來說,將使用Python+OpenCV實現模板匹配算法,以自動識別卡的類型和以及16位卡號數字。
在比較數字時,模板匹配是一種非常快速的方法。
為此將圖像處理管道分為4個步驟:
通過各種圖像處理技術檢測信用卡上四組四個數字,包括形態學操作、閾值和輪廓提取。 從四個分組中提取每個單獨的數字,得到16個需要分類的數字。 將模板匹配應用于每個數字,將其與OCR-A字體進行比較,以獲得數字分類。 檢查信用卡號的第一位數字以確定發卡公司。在對信用卡OCR系統進行評估后,發現如果發卡信用卡公司使用OCR-A字體作為數字,該系統的準確率為100%。 優化可以考慮在野外采集信用卡的真實圖像,并訓練機器學習模型(通過標準特征提取或訓練或卷積神經網絡),以進一步提高此系統的準確性。
1. 效果圖首先了解一下卡的組成:

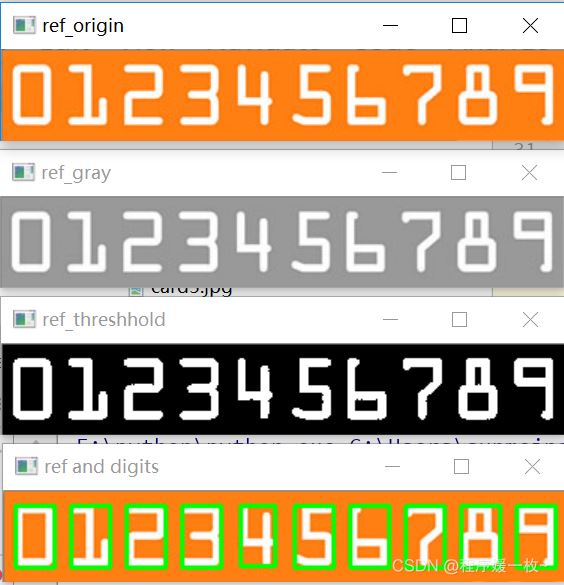
OCR-A 參考字體識別如下:原始圖 VS 灰度圖 VS 閾值化圖 VS 輪廓每個數字提取圖:灰度圖:忽略顏色對輪廓提取的影響閾值化圖:使得輪廓在前景白色,背景黑色便于輪廓提取。輪廓提取圖:提取每個數字ROI并記錄,方便后續對比卡片中的區域以識別出對應的數字。
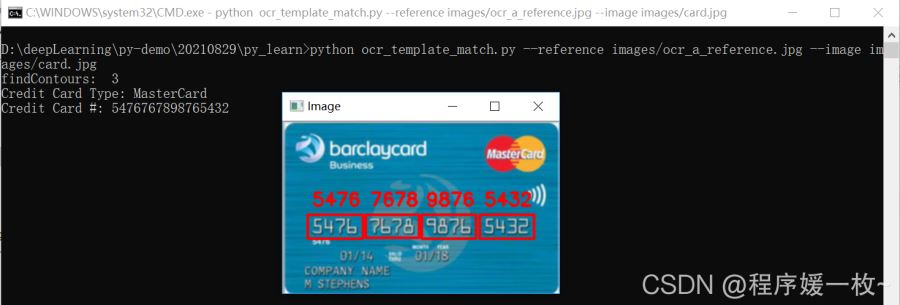
以下卡號均是演示卡,正確的識別卡的類型和卡號,效果圖1:
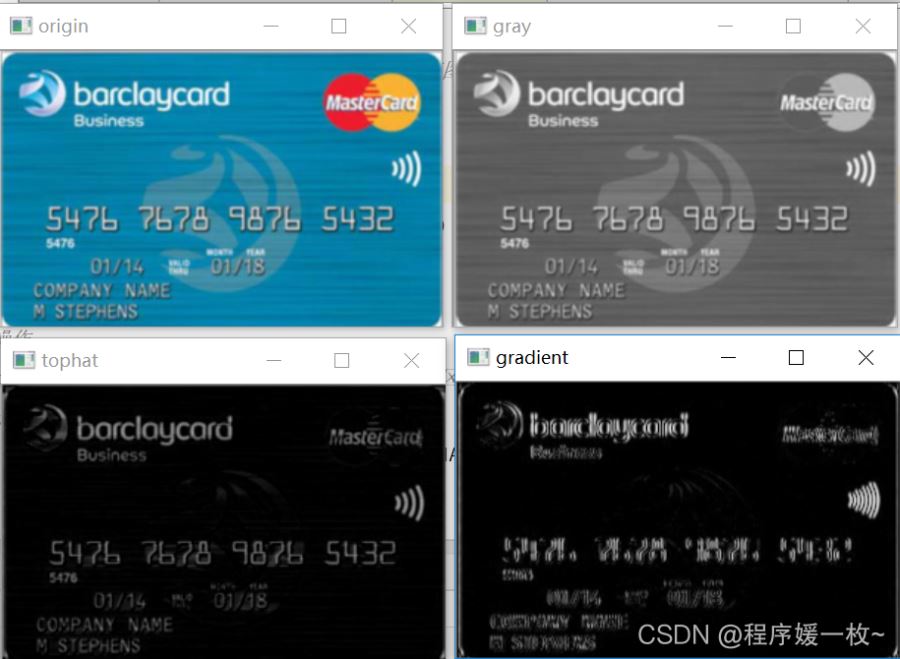
識別過程1——原圖 VS 灰度圖 VS 白帽圖 VS 梯度圖如下:灰度圖:忽略色彩影響白帽圖:從較暗的背景中提取較亮的區域梯度圖:計算Schaar梯度圖,便于了解圖像的色彩分配及提取;
識別過程2——形態學閉合圖 VS 二值化圖1 VS 閾值化圖2 如下:形態學閉合圖:矩形框形態學閉合操作,以幫助閉合信用卡數字之間的小的縫隙二值化圖:以便于提取閾值化圖:方形框形態學閉合操作,以二次幫助閉合信用卡數字區域之間的縫隙

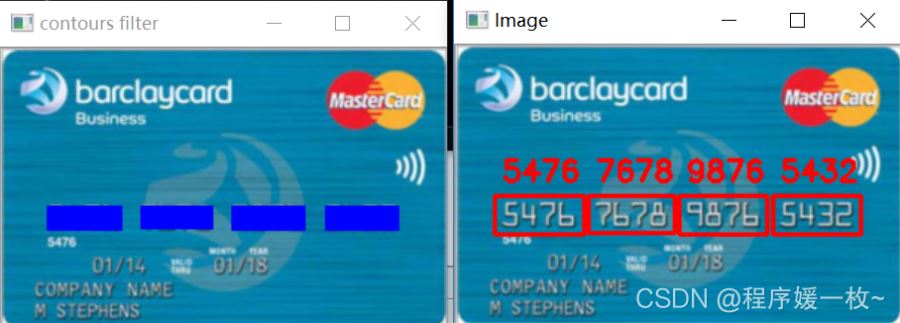
識別過程3——輪廓過濾圖 VS 提取最終效果圖 如下:輪廓過濾圖:根據面積及縱橫比,只保留卡片中的卡號區最終效果圖:提取4組4數字每一個組,然后對每一個組中的4個數字進行截取ROI并識別,并與之前存儲的數字ROI進行模板匹配,選取匹配值最高的作為最終結果。
OCR-A字體,是一種專門用于輔助光學字符識別算法的字體。
主要分為:
檢測圖像中信用卡的位置;本地化信用卡上的四組四位數字;應用OCR識別信用卡上的16位數字;識別信用卡的類型。
Tesseract庫在某些情況無法正確識別數字(這可能是因為Tesseract未接受信用卡示例字體培訓)。
2.2 檢測過程步驟在字典中存儲卡類型映射關系(卡號的第一位數字代表卡類型)。獲取參考圖像并提取數字。將數字模板存儲在字典中。本地化四個信用卡號組,每個組有四位數字(總共16位)。提取要“匹配”的數字。對每個數字執行模板匹配,將每個單獨的ROI與每個數字模板0-9進行比較,同時存儲每個嘗試匹配的分數。查找每個候選數字的最高分數,并構建一個名為“輸出”的列表。其中包含信用卡號。將信用卡號和信用卡類型輸出到終端,并將輸出圖像顯示到屏幕上。
2.3 優化使用OpenCV和Python匹配OCR腳本的模板在100%的時間內正確識別了16位數字中的每一位。然而在將OCR圖像應用于真實的信用卡圖像時,考慮到照明條件、視角和其他一般噪音的變化,可能需要采取更面向機器學習的方法。
3. 源代碼# 信用卡類型及卡號OCR系統# USAGE# python ocr_template_match.py --reference images/ocr_a_reference.png --image images/credit_card_05.pngimport argparseimport cv2import imutilsimport numpy as np# 導入必要的包from imutils import contours# 構建命令行參數及解析# --image 必須 要進行OCR的輸入圖像# --reference 必須 參考OCR-A圖像ap = argparse.ArgumentParser()ap.add_argument('-i', '--image', required=True,help='path to input image')ap.add_argument('-r', '--reference', required=True,help='path to reference OCR-A image')args = vars(ap.parse_args())# 定義一個字典(映射信用卡第一位數字和信用卡類型的編號)FIRST_NUMBER = { '3': 'American Express', '4': 'Visa', '5': 'MasterCard', '6': 'Discover Card'}# 從磁盤加載參考OCR-A圖像,轉換為灰度圖,閾值化圖像以顯示為白色前景和黑色背景# 并反轉圖像# and invert it, such that the digits appear as *white* on a *black*ref_origin = cv2.imread(args['reference'])cv2.imshow('ref_origin', ref_origin)ref = ref_origin.copy()ref = cv2.cvtColor(ref, cv2.COLOR_BGR2GRAY)cv2.imshow('ref_gray', ref)ref = cv2.threshold(ref, 180, 255, cv2.THRESH_BINARY)[1]cv2.imshow('ref_threshhold', ref)cv2.waitKey(0)# 尋找OCR-A圖像中的輪廓(數字的外輪廓線)# 并從左到右排序輪廓,初始化一個字典來存儲數字ROIrefCnts = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)print(’findContours: ’, len(refCnts))refCnts = imutils.grab_contours(refCnts)refCnts = contours.sort_contours(refCnts, method='left-to-right')[0]digits = {}# 遍歷OCR-A輪廓for (i, c) in enumerate(refCnts): # 計算數字的邊界框,提取它,縮放到固定的大小 (x, y, w, h) = cv2.boundingRect(c) cv2.rectangle(ref_origin, (x, y), (x + w, y + h), (0, 255, 0), 2) roi = ref[y:y + h, x:x + w] roi = cv2.resize(roi, (57, 88)) # 更新數字字典,數字匹配ROI digits[i] = roicv2.imshow('ref and digits', ref_origin)cv2.waitKey(0)# 初始化矩形和方形結構內核# 在圖像上滑動它來進行(卷積)操作,如模糊、銳化、邊緣檢測或其他圖像處理操作。# 使用矩形函數作為Top-hat形態學運算符,使用方形函數作為閉合運算。rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))# 準備進行OCR的輸入圖像# 加載輸入圖像,保持縱橫比縮放圖像寬度為300,轉換為灰度圖origin = cv2.imread(args['image'])origin = imutils.resize(origin, width=300)image = origin.copy()cv2.imshow('origin', origin)gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)cv2.imshow('gray', gray)# 執行形態學操作# 應用tophat(白帽)形態學操作以在暗的背景中提取出亮的區域(信用卡上的數字卡號)# Top hat操作在深色背景(即信用卡號)下顯示淺色區域tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)cv2.imshow('tophat', tophat)# 計算Scharr梯度,計算梯度值# 在白色禮帽上,計算x方向的Scharr梯度,然后縮放到范圍[0, 255]gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)gradX = np.absolute(gradX)(minVal, maxVal) = (np.min(gradX), np.max(gradX))# 最小/最大歸一化, 由float轉換gradX到uint8范圍[0-255]gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))gradX = gradX.astype('uint8')cv2.imshow('gradient', gradX)# 使用矩形框應用閉合操作以幫助閉合信用卡數字之間的小的縫隙# 應用Otsu’s閾值方法二值化圖像gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)cv2.imshow('morphologyEx', gradX)thresh = cv2.threshold(gradX, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]cv2.imshow('thresh1', thresh)# 在二值化圖像上,應用二次閉合操作# 再一次方形框形態學操作,幫助閉合信用卡數字區域之間的縫隙thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)cv2.imshow('thresh2', thresh)# 閾值圖像中查找輪廓,然后初始化數字位置列表cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)cnts = imutils.grab_contours(cnts)locs = []# 遍歷輪廓for (i, c) in enumerate(cnts): # 計算輪廓的邊界框,并計算縱橫比 (x, y, w, h) = cv2.boundingRect(c) ar = w / float(h) # 由于信用卡有固定的4組4數字,可以根據縱橫比來尋找潛在的輪廓 if ar > 2.5 and ar < 4.0:# 輪廓可以在最小/最大寬度上進一步修剪if (w > 40 and w < 55) and (h > 10 and h < 20): # 添加數字組輪廓的編輯框輪廓到位置list locs.append((x, y, w, h)) cv2.rectangle(origin, (x, y), (x + w, y + h), (255, 0, 0), -1)cv2.imshow('contours filter', origin)# 突出顯示信用卡上四組四位數字(總共十六位)。# 從左到右排序輪廓,并初始化list來存儲信用卡數字列表locs = sorted(locs, key=lambda x: x[0])output = []# 遍歷四組四位數字for (i, (gX, gY, gW, gH)) in enumerate(locs): # 初始化存放每組數字的list groupOutput = [] # 提取每組4位數字的灰度圖ROI # 應用閾值方法從背景信用卡中分割數字 group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5] group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] # 檢測組中每個單獨數字的輪廓 # 從左到右排序輪廓 digitCnts = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) digitCnts = imutils.grab_contours(digitCnts) digitCnts = contours.sort_contours(digitCnts, method='left-to-right')[0] # 遍歷數字輪廓 for c in digitCnts:# 計算每個單獨數字的邊界框# 提取數字,縮放以擁有和參考OCR-A字體模板圖像相同的大小(x, y, w, h) = cv2.boundingRect(c)roi = group[y:y + h, x:x + w]roi = cv2.resize(roi, (57, 88))# 初始化模板匹配分數listscores = []# 遍歷參考數字名和數字ROIfor (digit, digitROI) in digits.items(): # 應用基于相關性的模板匹配,計算分數,更新分數list # apply correlation-based template matching, take the # score, and update the scores list result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF) (_, score, _, _) = cv2.minMaxLoc(result) scores.append(score)# 數字ROI的分類將取 模板匹配分數中分數最大的參考數字# the classification for the digit ROI will be the reference# digit name with the *largest* template matching scoregroupOutput.append(str(np.argmax(scores))) # 圍繞每組畫一個矩形,并以紅色文本標識圖像上的信用卡號 # 繪制每組的數字識別分類結果 cv2.rectangle(image, (gX - 5, gY - 5), (gX + gW + 5, gY + gH + 5), (0, 0, 255), 2) cv2.putText(image, ''.join(groupOutput), (gX, gY - 15),cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2) # 更新輸出數字分組列表 # Pythonic的方法是使用extend函數,它將iterable對象的每個元素(本例中為列表)追加到列表的末尾 output.extend(groupOutput)# 顯示檢測到的信用卡類型和卡號到屏幕上print('Credit Card Type: {}'.format(FIRST_NUMBER[output[0]]))print('Credit Card #: {}'.format(''.join(output)))cv2.imshow('Image', image)cv2.waitKey(0)
參考 https://www.pyimagesearch.com/2017/07/17/credit-card-ocr-with-opencv-and-python/
到此這篇關于使用Pyhton+OpenCV進行卡類型及16位卡號數字的OCR功能的文章就介紹到這了,更多相關Pyhton+OpenCV卡號數字識別內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備