關于Java下奇怪的Base64詳解
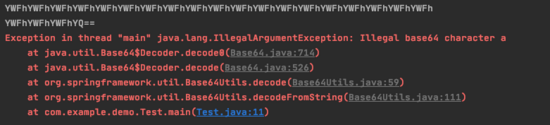
下面這一段代碼中會報錯。
package jiangbo.java.lang;import java.io.IOException;import java.nio.charset.Charset;import javax.xml.bind.DatatypeConverter;import sun.misc.BASE64Decoder;import sun.misc.BASE64Encoder;public class Base64Demo { public static void main(String[] args) throws IOException { String name = 'jiangbo'; Charset utf8 = Charset.forName('UTF-8'); BASE64Encoder base64Encoder = new sun.misc.BASE64Encoder(); String BASE64EncoderString = base64Encoder.encode(name.getBytes(utf8)); System.out.println(BASE64EncoderString); BASE64Decoder base64Decoder = new sun.misc.BASE64Decoder(); byte[] decodeBuffer = base64Decoder.decodeBuffer(BASE64EncoderString); System.out.println(new String(decodeBuffer, utf8)); String base64String = DatatypeConverter.printBase64Binary(name.getBytes(utf8)); System.out.println(base64String); byte[] base64Binary = DatatypeConverter.parseBase64Binary(base64String); System.out.println(new String(base64Binary, utf8)); }}

接下來我們分別查看一些這兩個代碼,我們發現 BASE64Encoder().encode 在進行base64編碼的時候進行了換行,換行符的ascii編碼對應的是 0x0a ,所以剛好命中這個報錯。
代碼實現如下,進行分別拆解。
public void decodeBuffer(InputStream var1, OutputStream var2) throws IOException { int var4 = 0; PushbackInputStream var5 = new PushbackInputStream(var1); this.decodeBufferPrefix(var5, var2); while(true) { try { int var6 = this.decodeLinePrefix(var5, var2); int var3; for(var3 = 0; var3 + this.bytesPerAtom() < var6; var3 += this.bytesPerAtom()) {this.decodeAtom(var5, var2, this.bytesPerAtom());var4 += this.bytesPerAtom(); } if (var3 + this.bytesPerAtom() == var6) {this.decodeAtom(var5, var2, this.bytesPerAtom());var4 += this.bytesPerAtom(); } else {this.decodeAtom(var5, var2, var6 - var3);var4 += var6 - var3; } this.decodeLineSuffix(var5, var2); } catch (CEStreamExhausted var8) { this.decodeBufferSuffix(var5, var2); return; } }}
首先 decodeLinePrefix 返回的是 bytesPerLine 定義的長度72。
public void decodeBuffer(InputStream var1, OutputStream var2) throws IOException { int var4 = 0; PushbackInputStream var5 = new PushbackInputStream(var1); this.decodeBufferPrefix(var5, var2); while(true) { try { int var6 = this.decodeLinePrefix(var5, var2); protected int decodeLinePrefix(PushbackInputStream var1, OutputStream var2) throws IOException { return this.bytesPerLine(); } protected int bytesPerLine() { return 72; }
緊接著調用 decodeAtom 進行處理,其中 bytesPerAtom 定義的數值是4。
int var3; for(var3 = 0; var3 + this.bytesPerAtom() < var6; var3 += this.bytesPerAtom()) {this.decodeAtom(var5, var2, this.bytesPerAtom());var4 += this.bytesPerAtom(); } protected int bytesPerAtom() { return 4;}
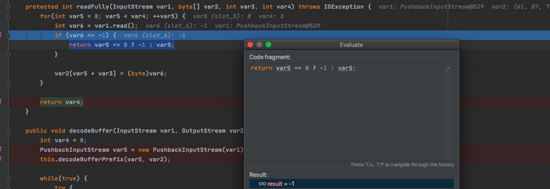
我們看看 decodeAtom 進行處理,先看看 readFully 方法。
protected void decodeAtom(PushbackInputStream var1, OutputStream var2, int var3) throws IOException { byte var5 = -1; byte var6 = -1; byte var7 = -1; byte var8 = -1; if (var3 < 2) { throw new CEFormatException('BASE64Decoder: Not enough bytes for an atom.'); } else { int var4; do { var4 = var1.read(); if (var4 == -1) {throw new CEStreamExhausted(); } } while(var4 == 10 || var4 == 13); this.decode_buffer[0] = (byte)var4; var4 = this.readFully(var1, this.decode_buffer, 1, var3 - 1);
在 readFully 當中,4個字節為一個單位組合,經過處理之后,結果是 [89,87,70,104] 。
89,87,70,104,61
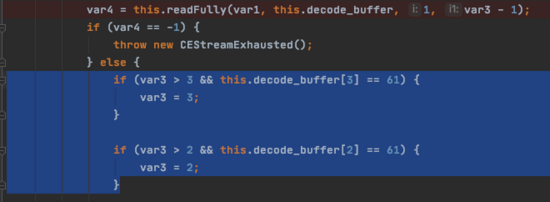
接著會繼續循環,那我們知道,這玩意嗎會按照4個字節為一個list去處理,前四個數據處理完之后,接下來的list是[61,,,],也就是說在readFully循環處理的過程中,返回結果是-1
當返回結果是-1的時候會進入 CEStreamExhausted 進行處理。
if (var4 == -1) { throw new CEStreamExhausted();
處理經過返回null,也就是說在這個異常里面是不會報錯退出的。
那我們繼續看看,假設我們把后面字節補齊,變成
89,87,70,104,61,61,61,61
可以看到經過處理之后變成[61,61,61,61]

0x61在ascii編碼里面代表 = ,進入到case 2進行處理。
89,87,70,104,61,61,61,61

實際可以看到 decode 處理數據是[97,97,97,-1]

我們在看看 java.util.base64.decode 這個decode詞法解析器,在這里面會進行兩種base64判斷。
private int decode0(byte[] src, int sp, int sl, byte[] dst) { int[] base64 = isURL ? fromBase64URL : fromBase64; int dp = 0; int bits = 0; int shiftto = 18; // pos of first byte of 4-byte atom while (sp < sl) { int b = src[sp++] & 0xff; if ((b = base64[b]) < 0) { if (b == -2) { // padding byte ’=’// = shiftto==18 unnecessary padding// x= shiftto==12 a dangling single x// x to be handled together with non-padding case// xx= shiftto==6&&sp==sl missing last =// xx=y shiftto==6 last is not =if (shiftto == 6 && (sp == sl || src[sp++] != ’=’) || shiftto == 18) { throw new IllegalArgumentException( 'Input byte array has wrong 4-byte ending unit');}break; } if (isMIME) // skip if for rfc2045continue; elsethrow new IllegalArgumentException( 'Illegal base64 character ' + Integer.toString(src[sp - 1], 16)); }
一種是判斷 YWFh= 中最后的 = ,也就是說 [89,87,70,104,61] 這個list經過運算之后如果是 = ,就會進行下面判斷,不符合規則就會報錯 Input byte array has wrong 4-byte ending unit 。
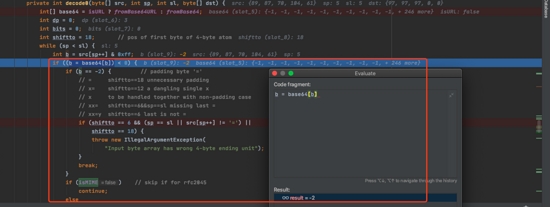
而下面 isMIME 判斷是來自 Decoder.RFC4648 ,默認是 false 。
public static byte[] decode(byte[] src) { return src.length == 0 ? src : Base64.getDecoder().decode(src);}public static Decoder getDecoder() { return Decoder.RFC4648;} static final Decoder RFC4648 = new Decoder(false, false); static final Decoder RFC4648_URLSAFE = new Decoder(true, false); static final Decoder RFC2045 = new Decoder(false, true);結語
簡單做個總結,也就是說用 sun.misc.BASE64Decoder 這個方法做 base64 解碼的時候,針對 base64 的兼容性更高,你在base64的字符串后面無論加多少個 = 都沒關系,但是在例如 java.util.base64.decode 這類型嚴格按照 base64 規范的進行解碼的方法下,就會出現報錯。
那有啥用呢,比如在一些base64編碼環境下,可能檢測用的是 java.util.base64.decode 方法,實際后面業務解碼用的是 sun.misc.BASE64Decoder 這樣在前后不一致的情況下,會出現繞過的問題。
到此這篇關于Java下奇怪的Base64的文章就介紹到這了,更多相關Java奇怪的Base64內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備