詳解python os.walk()方法的使用
os.walk方法是python中幫助我們高效管理文件、目錄的工具,在深度學習中數(shù)據(jù)整理應用的很頻繁,如數(shù)據(jù)集的名稱格式化、將數(shù)據(jù)集的按一定比例劃分訓練集train_set、測試集test_set。
1.導入文件(使用os.walk方法前需要導入以下包)
import osimport random # 后續(xù)用來將數(shù)據(jù)隨機打亂和生成確定隨機種子,保證每次生成的隨機數(shù)據(jù)一樣便于測試模型精準度
2.os.walk()參數(shù)解釋
os.walk(top, topdown=True, οnerrοr=None, followlinks=False)(后兩個參數(shù)我?guī)缀鯖]用過)參數(shù)
--top 我們需要遍歷的文件夾的地址(最好使用絕對地址,相對地址有時會出現(xiàn)未知錯誤)--topdown 該參數(shù)為True時,會優(yōu)先遍歷top目錄,否則優(yōu)先遍歷top的子目錄(默認值為 True)--onerror 需要一個 callable 對象,當walk需要異常時會調(diào)用--followlinks 如果為真,則會遍歷目錄下的快捷方式(linux 下是 symbolic link)實際所指的目錄(默認關閉)
os.walk 的返回值是一個生成器(generator),也就是說我們可以用循環(huán)去不遍歷它,來獲得其內(nèi)容。每次遍歷的對象都是返回的是一個三元組(root,dirs,files)
--root 指的是當前正在遍歷的這個文件夾的本身的地址--dirs 返回的是一個列表list,表中數(shù)據(jù)是該文件夾中所有的目錄的名稱(但不包括子目錄名稱)--files 返回的也是一個列表list , 表中數(shù)據(jù)是該文件夾中所有的文件名稱(但不包括子目錄名稱)
3.用于測試文件夾組織結構
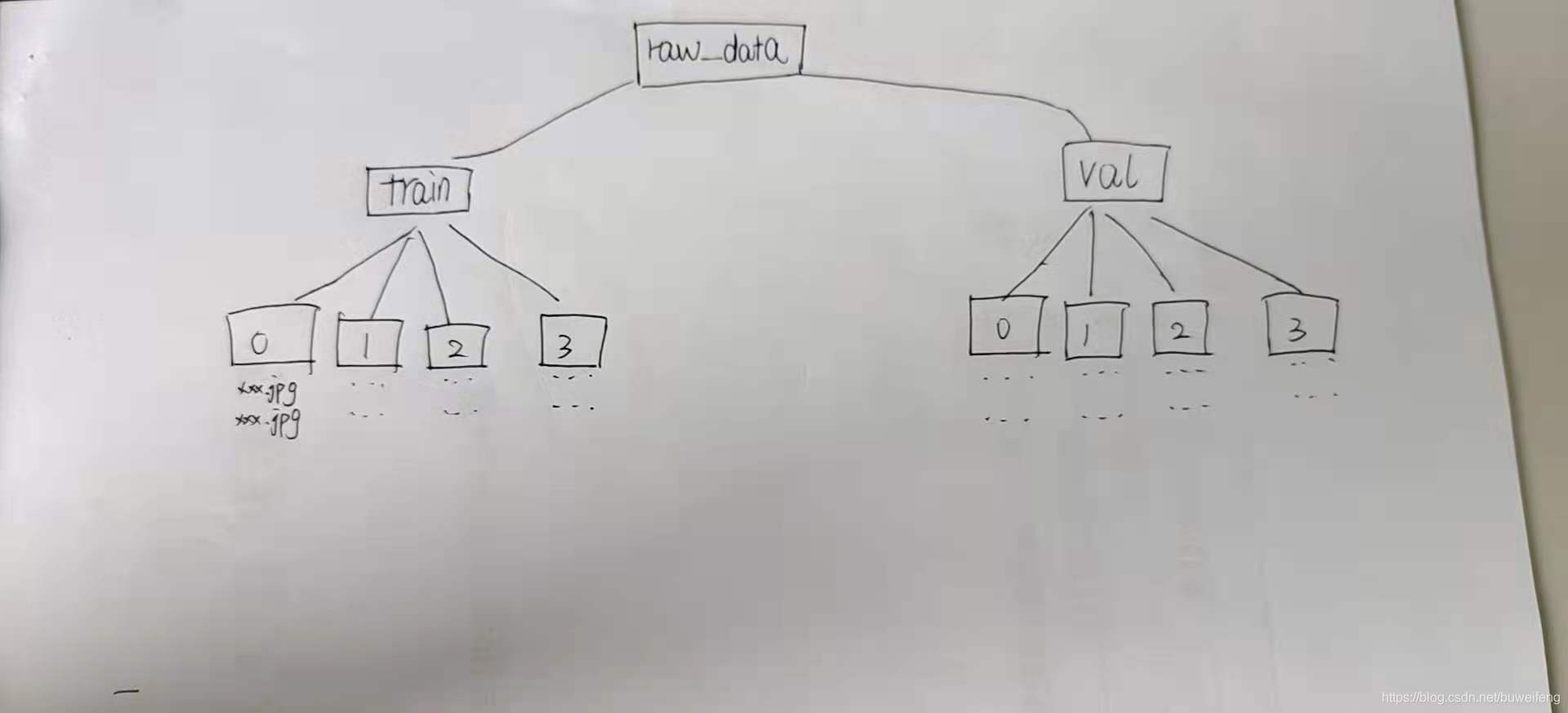 4.
4.
廢話不說,看測試例子
4.1 os.walk(top, topdown=True)時打印返回的 root,dirs,files,順便測試下topdown為真和假時的遍歷順序的區(qū)別。(這里就不展示運行后的結果了,代碼拿走直接就可運行)
# topdown=True(該參數(shù)默認為真)def _get_img_info(): #測試時將data_dir 換為自己的目標文件夾即可 data_dir = r’C:UsersfutiangeDesktopZero to Heroexpression_testraw_data’ for root,dirs,files in os.walk(data_dir,topdown=True):print(’root={}’.format(root))print(’dirs={}’.format(dirs))print(’files={}’.format(files))if __name__ == ’__main__’: _get_img_info()# topdown=False(該參數(shù)默認為假) def _get_img_info(): data_dir = r’C:UsersfutiangeDesktopZero to Heroexpression_testraw_data’ for root,dirs,files in os.walk(data_dir,topdown=False):print(’root={}’.format(root))print(’dirs={}’.format(dirs))print(’files={}’.format(files))if __name__ == ’__main__’: _get_img_info()
4.2 使用案例
在深度學習中遍歷數(shù)據(jù)集時,我們可以對數(shù)據(jù)集劃分,這里按train :test = 9 : 1劃分。
import osimport random # 后續(xù)用來將數(shù)據(jù)隨機打亂和生成確定隨機種子,保證每次生成的隨機數(shù)據(jù)一樣便于測試模型精準度def _get_img_info(rng_seed,split_n,mode): image_path_list = [] #用來存放圖片的路徑 label_path_list = [] #用來存放圖片對應的標簽 data_dir = r’C:UsersfutiangeDesktopZero to Heroexpression_testraw_data’ for root,dirs,files in os.walk(data_dir):for file in files: path_file = os.path.join(root,file) print(path_file) if path_file.endswith('.jpg'): #判斷該路徑下文件是不是以.jpg結尾#print(os.path.basename(root)) #輸出圖片路徑#print(os.path.basename(root)[0]) #輸出該圖片所在的文件夾的第一個字符,我這里文件夾的第一個字符就是圖片的標簽,測試時可以根據(jù)自己的文件夾名稱更改#print(int(os.path.basename(root)[0]))image_path_list.append(path_file) #將圖片路徑加入列表label_path_list.append(os.path.basename(root)[0]) #根據(jù)文件夾名稱確定標簽,并加入列表 data_info = [[n,l] for n,l in zip(image_path_list,label_path_list)] #將圖片路徑-標簽 關聯(lián)起來 random.seed(rng_seed) # 該方法中傳入?yún)?shù),確保每次生成的種子都是一樣的 random.shuffle(data_info) #上一行代碼生成的種子是確定的,保證了每次將列表元素打亂后的結果一樣,便于測試模型性能 split_idx = int(len(data_info) * split_n) # data_len * 0.9 # split_n代表數(shù)據(jù)集劃分的比例 if mode == ’train’:img_set = data_info[:split_idx] elif mode == ’val’:img_set = data_info[split_idx:] else:raise Exception('mode 無法識別,僅支持(train,valid)') return img_set #返回隨機打亂后的數(shù)據(jù)集,后續(xù)在對其進行格式化即可將數(shù)據(jù)集加載進模型測試if __name__ == ’__main__’: _get_img_info(1,0.9,’train’)
到此這篇關于詳解python os.walk()方法的使用的文章就介紹到這了,更多相關python os.walk()方法內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持好吧啦網(wǎng)!
相關文章:
1. 低版本IE正常運行HTML5+CSS3網(wǎng)站的3種解決方案2. jsp實現(xiàn)局部刷新頁面、異步加載頁面的方法3. xml文件的結構解讀第1/2頁4. Jsp中request的3個基礎實踐5. 使用python修改文件并立即寫回到原始位置操作(inplace讀寫)6. python GUI庫圖形界面開發(fā)之PyQt5工具欄控件QToolBar的詳細使用方法與實例7. 什么是python的id函數(shù)8. python GUI庫圖形界面開發(fā)之PyQt5計數(shù)器控件QSpinBox詳細使用方法與實例9. Python填充任意顏色,不同算法時間差異分析說明10. Java map.getOrDefault()方法的用法詳解

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備