MySQL百萬數(shù)據(jù)深度分頁優(yōu)化思路解析
目錄
- 業(yè)務(wù)場(chǎng)景
- 瓶頸再現(xiàn)
- 問題分析
- 回表
- 覆蓋索引
- IO
- LIMTI 2000,10 ?
- 問題總結(jié)
- 解決方案
- 優(yōu)化前后性能對(duì)比
業(yè)務(wù)場(chǎng)景
一般在項(xiàng)目開發(fā)中會(huì)有很多的統(tǒng)計(jì)數(shù)據(jù)需要進(jìn)行上報(bào)分析,一般在分析過后會(huì)在后臺(tái)展示出來給運(yùn)營和產(chǎn)品進(jìn)行分頁查看,最常見的一種就是根據(jù)日期進(jìn)行篩選。這種統(tǒng)計(jì)數(shù)據(jù)隨著時(shí)間的推移數(shù)據(jù)量會(huì)慢慢的變大,達(dá)到百萬、千萬條數(shù)據(jù)只是時(shí)間問題。
瓶頸再現(xiàn)
創(chuàng)建了一張user表,給create_time字段添加了索引。并在該表中添加了100w條數(shù)據(jù)。
我們這里使用limit分頁的方式查詢下前5條數(shù)據(jù)和后5條數(shù)據(jù)在查詢時(shí)間上有什么區(qū)別。
查詢前10條基本上不消耗什么時(shí)間

我們從第50w+開始取數(shù)據(jù)的時(shí)候,查詢耗時(shí)1秒。

SQL_NO_CACHE
這個(gè)關(guān)鍵詞是為了不讓SQL查詢走緩存。
同樣的SQL語句,不同的分頁條件,兩者的性能差距如此之大,那么隨著數(shù)據(jù)量的增長,往后頁的查詢所耗時(shí)間按理會(huì)越來越大。
問題分析
回表
我們一般對(duì)于查詢頻率比較高的字段會(huì)建立索引。索引會(huì)提高我們的查詢效率。我們上面的語句使用了SELECT * FROM user,但是我們并不是所有的字段都建立了索引。當(dāng)從索引文件中查詢到符合條件的數(shù)據(jù)后,還需要從數(shù)據(jù)文件中查詢到?jīng)]有建立索引的字段。那么這個(gè)過程稱之為回表。
覆蓋索引
如果查詢的字段正好創(chuàng)建了索引了,比如 SELECT create_time FROM user,我們查詢的字段是我們創(chuàng)建的索引,那么這個(gè)時(shí)候就不需要再去數(shù)據(jù)文件里面查詢,也就不需要回表。這種情況我們稱之為覆蓋索引。
IO
回表操作通常是IO操作,因?yàn)樾枰鶕?jù)索引查找到數(shù)據(jù)行后,再根據(jù)數(shù)據(jù)行的主鍵或唯一索引去聚簇索引中查找具體的數(shù)據(jù)行。聚簇索引一般是存儲(chǔ)在磁盤上的數(shù)據(jù)文件,因此在執(zhí)行回表操作時(shí)需要從磁盤讀取數(shù)據(jù),而磁盤IO是相對(duì)較慢的操作。
LIMTI 2000,10 ?
你有木有想過LIMIT 2000,10會(huì)不會(huì)掃描1-2000行,你之前有沒有跟我一樣,覺得數(shù)據(jù)是直接從2000行開始取的,前面的根本沒掃描或者不回表。其實(shí)這樣的寫法,一個(gè)完整的流程是查詢數(shù)據(jù),如果不能覆蓋索引,那么也是要回表查詢數(shù)據(jù)的。
現(xiàn)在你知道為什么越到后面查詢?cè)铰税桑?/p>
問題總結(jié)
我們現(xiàn)在知道了LIMIT 遇到后面查詢的性能越差,性能差的原因是因?yàn)橐乇恚热灰呀?jīng)找到了問題那么我們只需要減少回表的次數(shù)就可以提升查詢性能了。
解決方案
既然覆蓋索引可以防止數(shù)據(jù)回表,那么我們可以先查出來主鍵id(主鍵索引),然后將查出來的數(shù)據(jù)作為臨時(shí)表然后 JOIN 原表就可以了,這樣只需要對(duì)查詢出來的5條結(jié)果進(jìn)行數(shù)據(jù)回表,大幅減少了IO操作。
優(yōu)化前后性能對(duì)比
我們看下執(zhí)行效果:
優(yōu)化前:1.4s
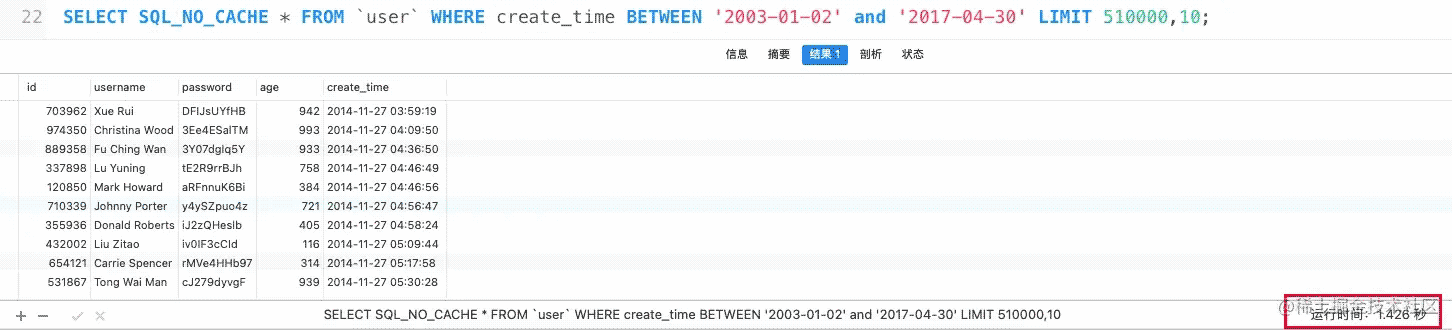
優(yōu)化后:0.2s

查詢耗時(shí)性能大幅提升。這樣如果分頁數(shù)據(jù)很大的話,也不會(huì)像普通的limit查詢那樣慢。
以上就是MySQL百萬數(shù)據(jù)深度分頁優(yōu)化思路分析的詳細(xì)內(nèi)容,更多關(guān)于MySQL數(shù)據(jù)分頁優(yōu)化的資料請(qǐng)關(guān)注其它相關(guān)文章!

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備