MySQL中in和exists區別詳解
為了大家學習方便,我在這里面建立兩張表并為其添加一些數據。
一張水果表,一張供應商表。
水果表 fruits表
f_id f_name f_price a1 apple 5 a2 appricot 2 b1 blackberry 10 b2 berry 8 c1 cocount 9
供應商表 suppliers表
s_id s_name 101 天虹 102 沃爾瑪 103 家樂福 104 華潤萬家
我們將用這兩張表做演示。
二、什么是existsexists關鍵字后面的參數是一個任意的子查詢,系統對子查詢進行運算以判斷它是否返回行,如果至少返回一行,那么exists的結果為true ,此時外層的查詢語句將進行查詢;如果子查詢沒有返回任何行,那么exists的結果為false,此時外層語句將不進行查詢。
需要注意的是,當我們的子查詢為 SELECT NULL 時,MYSQL仍然認為它是True。
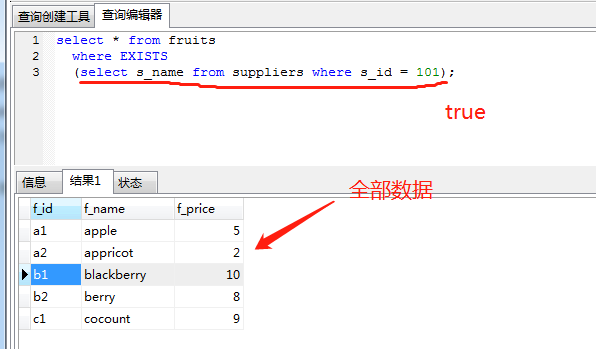
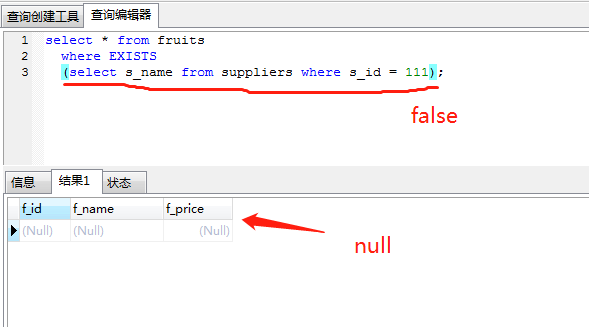
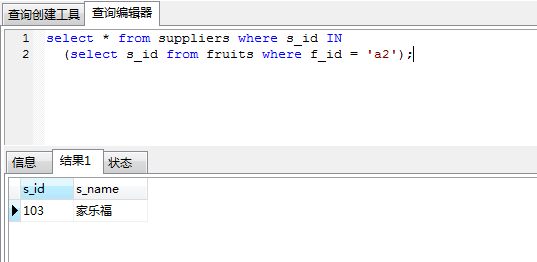
in 關鍵字進行子查詢時,內層查詢語句僅僅返回一個數據列,這個數據列的值將提供給外層查詢語句進行比較操作。
為了測試in 關鍵字,我在水果表中加了s_id一列
水果表 fruits表
f_id f_name f_price s_id a1 apple 5 101 a2 appricot 2 103 b1 blackberry 10 102 b2 berry 8 104 c1 cocount 9 103
in和exists到底有啥區別那,要什么時候用in,什么時候用exists?
我們先記住口訣再說細節!“外層查詢表小于子查詢表,則用exists,外層查詢表大于子查詢表,則用in,如果外層和子查詢表差不多,則愛用哪個用哪個。”
我想你已經看出來了,當fruits表數據很大的時候不適合用in,因為它最多會將fruits表數據全部遍歷一次。
如:suppliers表有10000條記錄,fruits表有1000000條記錄,那么最多有可能遍歷10000*1000000次,效率很差。
再如:suppliers表有10000條記錄,fruits表有100條記錄,那么最多有可能遍歷10000*100次,遍歷次數大大減少,效率大大提升。
但是:suppliers表有10000條記錄,fruits表有100條記錄,那么exists()還是執行10000次,還不如使用in()遍歷10000*100次,因為in()是在內存里遍歷,而exists()需要查詢數據庫,我們都知道查詢數據庫所消耗的性能更高,而內存比較很快。
因此我們只需要記住口訣:“外層查詢表小于子查詢表,則用exists,外層查詢表大于子查詢表,則用in,如果外層和子查詢表差不多,則愛用哪個用哪個。”
五、not exists和not in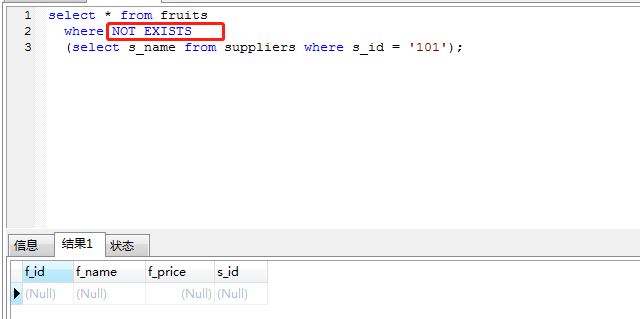
和exists一樣,用到了suppliers上的id索引,exists()執行次數為fruits.length,不緩存exists()的結果集。
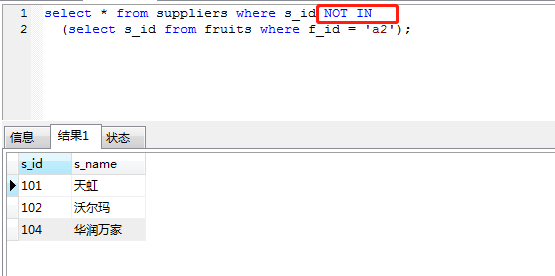
因為not in實質上等于!= and != ···,因為!=不會使用索引,故not in不會使用索引。
為啥not in不會使用索引?我們假設有100萬數據,s_id只有0和1兩個值,利用索引我們要先讀索引文件,然后二分查找,找到對應的數據磁盤指針,再根據讀到的指針在磁盤上對應的數據,影響結果集50萬,這種情況,和直接全表掃描哪個快顯而易見。
如果你s_id字段是一個unique,就會用到索引。
如果你一定要用索引,可以用force index,不過效率不會有改善一般還會更慢就是了。
合理使用索引,Cardinality是一個重要指標,太小的話跟沒建沒區別,還浪費空間。
因此,不管suppliers和fruits大小如何,均使用not exists效率會更高。
到此這篇關于MySQL中in和exists區別詳解的文章就介紹到這了,更多相關MySQL in和exists區別內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備