python實現圖像識別的示例代碼
首先我們需要安裝PIL和pytesseract庫。PIL:(Python Imaging Library)是Python平臺上的圖像處理標準庫,功能非常強大。pytesseract:圖像識別庫。
我這里使用的是python3.6,PIL不支持python3所以使用如下命令
pip install pytesseractpip install pillow
如果是python2,則在命令行執行如下命令:
pip install pytesseractpip install PIL
這時候我們去運行上面的代碼會發現如下錯誤:

錯誤提示的很明顯:No such file or directory :'tesseract'
這是因為我們沒有安裝tesseract-ocr引擎
二、tesseract-ocr引擎光學字符識別(OCR,Optical Character Recognition)是指對文本資料進行掃描,然后對圖像文件進行分析處理,獲取文字及版面信息的過程。OCR技術非常專業,一般多是印刷、打印行業的從業人員使用,可以快速的將紙質資料轉換為電子資料。關于中文OCR,目前國內水平較高的有清華文通、漢王、尚書,其產品各有千秋,價格不菲。國外OCR發展較早,像一些大公司,如IBM、微軟、HP等,即使沒有推出單獨的OCR產品,但是他們的研發團隊早已掌握核心技術,將OCR功能植入了自身的軟件系統。對于我們程序員來說,一般用不到那么高級的,主要在開發中能夠集成基本的OCR功能就可以了。這兩天我查找了很多免費OCR軟件、類庫,特地整理一下,今天首先來談談Tesseract,下一次將討論下Onenote 2010中的OCR API實現。可以在這里查看OCR技術的發展簡史。Tesseract的OCR引擎最先由HP實驗室于1985年開始研發,至1995年時已經成為OCR業內最準確的三款識別引擎之一。然而,HP不久便決定放棄OCR業務,Tesseract也從此塵封。數年以后,HP意識到,與其將Tesseract束之高閣,不如貢獻給開源軟件業,讓其重煥新生--2005年,Tesseract由美國內華達州信息技術研究所獲得,并求諸于Google對Tesseract進行改進、消除Bug、優化工作。
###安裝tesseract-ocr引擎
brew install tesseract
然后我們通過tesseract -v看一下是否安裝成成功
tesseract 3.05.01leptonica-1.75.0libjpeg 9b : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11
這時候我們運行上面代碼會出現亂碼

這是因為tesseract默認只有語言包中沒有中文包,如下圖:
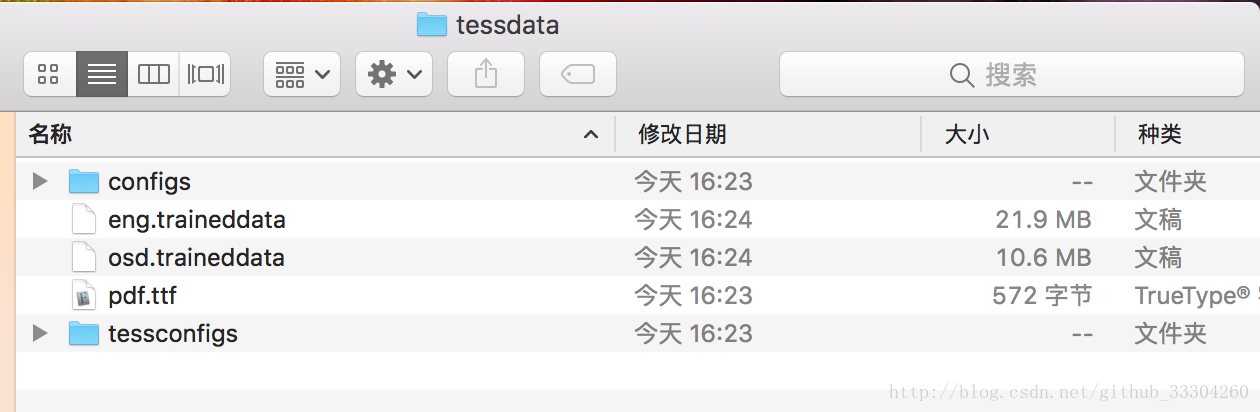
###安裝tesseract-ocr語言包我們去GitHub下載我們需要的語言包,這里我只下載了chi_tra.traineddata和chi_sim.traineddatagithub:tesseract-ocr/tessdata然后放到/usr/local/Cellar/tesseract/3.05.01/share/tessdata路徑下面。
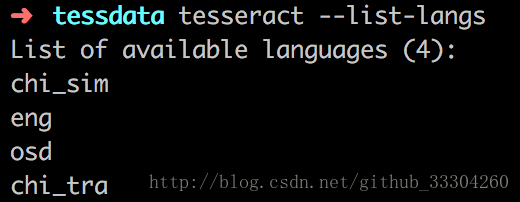
可以通過tesseract --list-langs查看本地語言包:
可以通過tesseract --help-psm 查看psm
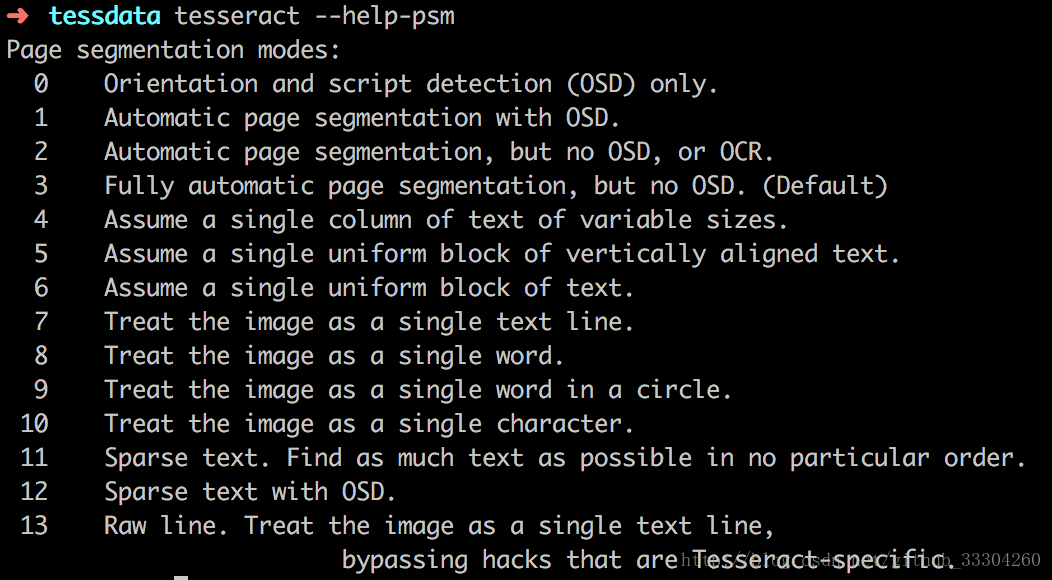
0:定向腳本監測(OSD)1: 使用OSD自動分頁2 :自動分頁,但是不使用OSD或OCR(Optical Character Recognition,光學字符識別)3 :全自動分頁,但是沒有使用OSD(默認)4 :假設可變大小的一個文本列。5 :假設垂直對齊文本的單個統一塊。6 :假設一個統一的文本塊。7 :將圖像視為單個文本行。8 :將圖像視為單個詞。9 :將圖像視為圓中的單個詞。10 :將圖像視為單個字符。
為什么這里要強調語言包和psm,因為我們在使用中會用到,比如多個語言包組合并且視為統一的文本塊將使用如下參數:
pytesseract.image_to_string(image,lang='chi_sim+eng',config='-psm 6')
這里我們通過+來合并使用多個語言包。
接下來我們看一下配置好一切的正確結果。
import pytesseractfrom PIL import Imageimage = Image.open('../pic/c.png')code = pytesseract.image_to_string(image,lang='chi_sim',config='-psm 6')print(code)


此時大公告成。
到此這篇關于python實現圖像識別的示例代碼的文章就介紹到這了,更多相關python 圖像識別內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備