python pandas模糊匹配 讀取Excel后 獲取指定指標(biāo)的操作
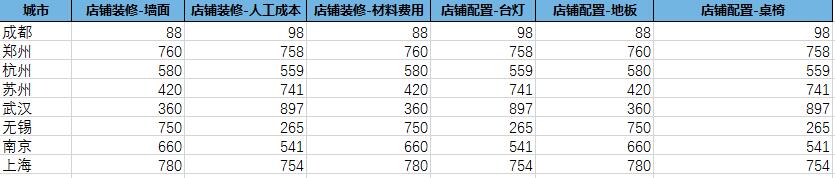
數(shù)據(jù)代表了各個(gè)城市店鋪的裝修和配置費(fèi)用,要統(tǒng)計(jì)出裝修和配置項(xiàng)的總費(fèi)用并進(jìn)行加和計(jì)算;
2.pandas實(shí)現(xiàn)過(guò)程import pandas as pd#1.讀取數(shù)據(jù)df = pd.read_excel(r’./data/pfee.xlsx’)print(df)
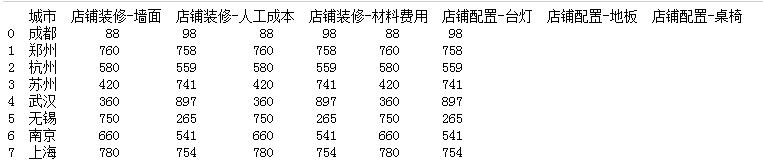
cols = list(df.columns)print(cols)

#2.獲取含有裝修 和 配置 字段的數(shù)據(jù)zx_lists=[]pz_lists=[]for name in cols: if ’裝修’ in name: zx_lists.append(name) elif ’配置’ in name: pz_lists.append(name)print(zx_lists)print(pz_lists)

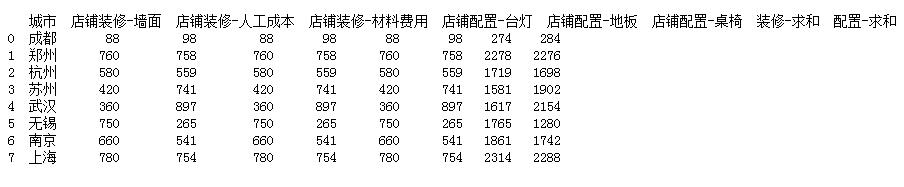
#3.對(duì)裝修和配置項(xiàng)費(fèi)用進(jìn)行求和計(jì)算df[’裝修-求和’] =df[zx_lists].apply(lambda x:x.sum(),axis=1)df[’配置-求和’] = df[pz_lists].apply(lambda x:x.sum(),axis=1)print(df)
補(bǔ)充:pandas 中dataframe 中的模糊匹配 與pyspark dataframe 中的模糊匹配
1.pandas dataframe匹配一個(gè)很簡(jiǎn)單,批量匹配如下
df_obj[df_obj[’title’].str.contains(r’.*?n.*’)] #使用正則表達(dá)式進(jìn)行模糊匹配,*匹配0或無(wú)限次,?匹配0或1次
pyspark dataframe 中模糊匹配有兩種方式
2.spark dataframe api, filter rlike 聯(lián)合使用df1=df.filter('uri rlike ’com.tencent.tmgp.sgame|%E8%80%85%E8%8D%A3%E8%80%80_|android.ugc.live| %e7%88f%e8%a7%86%e9%a2%91|%E7%%8F%E8%A7%86%E9%A2%91’').groupBy('uri'). count().sort('count', ascending=False)
注意點(diǎn):
1.rlike 后面進(jìn)行批量匹配用引號(hào)包裹即可
2.rlike 中要匹配特殊字符的話,不需要轉(zhuǎn)義
3.rlike ’bappleb’ 雖然也可以匹配但是匹配數(shù)量不全,具體原因不明,歡迎討論。
In [5]: df.filter('name rlike ’%’').show()+---+------+-----+|age|height| name|+---+------+-----+| 4| 140|A%l%i|| 6| 180| i%ce|+---+------+-----+3.spark sql
spark.sql('select uri from t where uri like ’%com.tencent.tmgp.sgame%’ or uri like ’douyu’').show(5)
如果要批量匹配的話,就需要在后面繼續(xù)添加uri like ’%blabla%’,就有點(diǎn)繁瑣了。
對(duì)了這里需要提到原生sql 的批量匹配,regexp 就很方便了,跟rlike 有點(diǎn)相似
mysql> select count(*) from url_parse where uri regexp ’android.ugc.live|com.tencent.tmgp.sgame’;+----------+| count(*) |+----------+| 9768 |+----------+1 row in set (0.52 sec)
于是這里就可以將sql中regexp 應(yīng)用到spark sql 中
In [9]: spark.sql(’select * from t where name regexp '%l|t|_'’).show()+---+------+------+|age|height| name|+---+------+------+| 1| 150|Al_ice|| 4| 140| A%l%i|+---+------+------+
以上為個(gè)人經(jīng)驗(yàn),希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。如有錯(cuò)誤或未考慮完全的地方,望不吝賜教。
相關(guān)文章:
1. 利用ajax+php實(shí)現(xiàn)商品價(jià)格計(jì)算2. Java實(shí)現(xiàn)UDP通信過(guò)程實(shí)例分析【服務(wù)器端與客戶端】3. JS圖片懶加載庫(kù)VueLazyLoad詳解4. Java PreparedStatement用法詳解5. Python 解決火狐瀏覽器不彈出下載框直接下載的問(wèn)題6. Java利用TCP協(xié)議實(shí)現(xiàn)客戶端與服務(wù)器通信(附通信源碼)7. 使用AJAX(包含正則表達(dá)式)驗(yàn)證用戶登錄的步驟8. Java實(shí)現(xiàn)的迷宮游戲9. HTML <!DOCTYPE> 標(biāo)簽10. Spring如何集成ibatis項(xiàng)目并實(shí)現(xiàn)dao層基類(lèi)封裝
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備