Python連接HDFS實現(xiàn)文件上傳下載及Pandas轉(zhuǎn)換文本文件到CSV操作
1. 目標
通過hadoop hive或spark等數(shù)據(jù)計算框架完成數(shù)據(jù)清洗后的數(shù)據(jù)在HDFS上
爬蟲和機器學習在Python中容易實現(xiàn)
在Linux環(huán)境下編寫Python沒有pyCharm便利
需要建立Python與HDFS的讀寫通道
2. 實現(xiàn)
安裝Python模塊pyhdfs
版本:Python3.6, hadoop 2.9
讀文件代碼如下
from pyhdfs import HdfsClientclient=HdfsClient(hosts=’ghym:50070’)#hdfs地址res=client.open(’/sy.txt’)#hdfs文件路徑,根目錄/for r in res: line=str(r,encoding=’utf8’)#open后是二進制,str()轉(zhuǎn)換為字符串并轉(zhuǎn)碼 print(line)
寫文件代碼如下
from pyhdfs import HdfsClientclient=HdfsClient(hosts=’ghym:50070’,user_name=’hadoop’)#只有hadoop用戶擁有寫權(quán)限str=’hello world’client.create(’/py.txt’,str)#創(chuàng)建新文件并寫入字符串
上傳本地文件到HDFS
from pyhdfs import HdfsClientclient = HdfsClient(hosts=’ghym:50070’, user_name=’hadoop’)client.copy_from_local(’d:/pydemo.txt’, ’/pydemo’)#本地文件絕對路徑,HDFS目錄必須不存在
3. 讀取文本文件寫入csv
Python安裝pandas模塊
確認文本文件的分隔符
# pyhdfs讀取文本文件,分隔符為逗號,from pyhdfs import HdfsClientclient = HdfsClient(hosts=’ghym:50070’, user_name=’hadoop’)inputfile=client.open(’/int.txt’)# pandas調(diào)用讀取方法read_tableimport pandas as pddf=pd.read_table(inputfile,encoding=’gbk’,sep=’,’)#參數(shù)為源文件,編碼,分隔符# 數(shù)據(jù)集to_csv方法轉(zhuǎn)換為csvdf.to_csv(’demo.csv’,encoding=’gbk’,index=None)#參數(shù)為目標文件,編碼,是否要索引
補充知識:記 讀取hdfs 轉(zhuǎn) pandas 再經(jīng)由pandas轉(zhuǎn)為csv的一個坑
工作流程是這樣的:
讀取 hdfs 的 csv 文件,采用的是 hdfs 客戶端提供的 read 方法,該方法返回一個生成器。
將讀取到的數(shù)據(jù)按 逗號 處理,變?yōu)橐粋€二維數(shù)組。
將二維數(shù)組傳給 pandas,生成 df。
經(jīng)若干處理后,將 df 轉(zhuǎn)為 csv 文件并寫入hdfs。
問題是這樣的:
正常的數(shù)據(jù):
ZERO,MEAN,STD,CV,INC,OPP,CS,IS_OUTNET
0,9.233,2.445,0.265,1.202,241,1,0
0,8.667,1.882,0.217,1.049,179,1,0
三行數(shù)據(jù),正常走流程,沒有任何問題。
異常數(shù)據(jù):
ZERO,MEAN,STD,CV,INC,OPP,CS,IS_OUTNET,probability,prediction
0,9.233,2.445,0.265,1.202,241,1,0,’[0.9653901649086855,0.03460983509131456]’,0.0
0,8.667,1.882,0.217,1.049,179,1,0,’[0.9653901649086855,0.03460983509131456]’,0.0
在每一行中都會有一個數(shù)組類似的數(shù)據(jù),有一對引號包起來,中間存在逗號,不可以拆分。
為此,我的做法如下:
匹配逗號是被成對引號包圍的字符串。
將匹配到的字符串中的逗號替換為特定字符。
將替換后的新字符串替換回原字符串。
在將原字符串中的特定字符串替換為逗號。
本來這樣做沒有什么問題,但是在經(jīng)由pandas轉(zhuǎn)為csv的時候,發(fā)現(xiàn)原來帶引號的字符串變?yōu)榱饲昂蟾鲙齻€引號。
源數(shù)據(jù):

處理后的數(shù)據(jù):
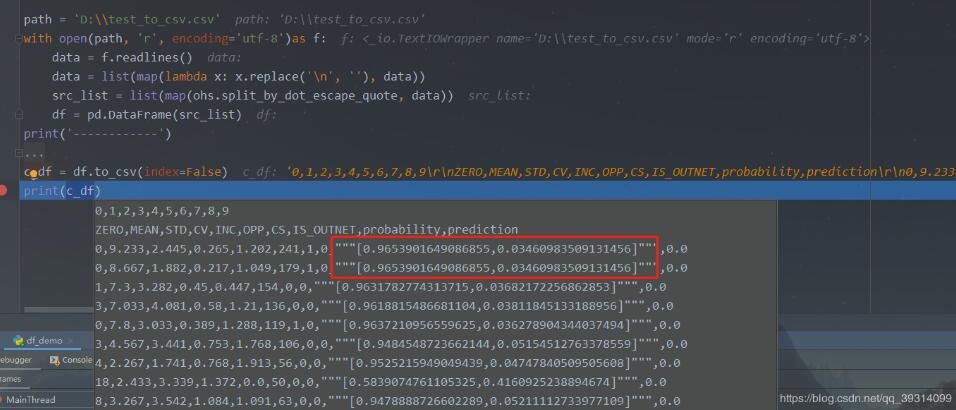
方法如下:

仔細研究對比了下數(shù)據(jù),發(fā)現(xiàn)數(shù)據(jù)里的引號其實只是在純文本文件中用來標識其為字符串,并不應該存在于實際數(shù)據(jù)中。

而我每次匹配后都是原封不動替換回去,譬如:
源數(shù)據(jù):
'[0.9653901649086855,0.03460983509131456]'
匹配替換后:
'[0.9653901649086855${dot}0.03460983509131456]'
這樣傳給pandas,它就會認為這個數(shù)據(jù)是帶引號的,在重新轉(zhuǎn)為csv的時候,就會進行轉(zhuǎn)義等操作,導致多出很多引號。
所以解決辦法就是在替換之前,將匹配時遇到的引號也去掉:
PATTERN = ’(?<=(?P<quote>[’']))([^,]+,[^,]+)+?(?=(?P=quote))’
中間 ([^,]+,[^,]+)+? 要用+?,因為必須確定是有這樣的組合才可以,并且非貪婪模式,故不可 ? 或者 *?

(ps:為了方便后面引用前面的匹配,我在環(huán)視匹配中創(chuàng)建了一個組)
再來個整體效果:

為了說明效果,引用pandas的自帶讀取csv方法:

可以看到pandas讀取出的該位置數(shù)據(jù)也是字符串,引號正是作為一個字符串聲明而存在。
再次修改正則:
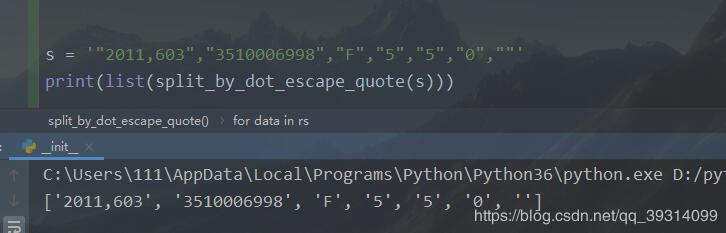
def split_by_dot_escape_quote(string): ''' 按逗號分隔字符串,若其中有引號,將引號內(nèi)容視為整體 ''' # 匹配引號中的內(nèi)容,非貪婪,采用正向肯定環(huán)視, # 當左引號(無論單雙引)被匹配到,放入組quote, # 中間的內(nèi)容任意,但是要用+?,非貪婪,且至少有一次匹配到字符, # 若*?,則匹配0次也可,并不會匹配任意字符(環(huán)視只匹配位置不匹配字符), # 由于在任意字符后面又限定了前面匹配到的quote,故只會匹配到', # +?則會限定前面必有字符被匹配,故'',或引號中任意值都可匹配到 pattern = re.compile(’(?=(?P<quote>[’'])).+?(?P=quote)’) rs = re.finditer(pattern, string) for data in rs: # 匹配到的字符串 old_str = data.group() # 將匹配到的字符串中的逗號替換為特定字符, # 以便還原到原字符串進行替換 new_str = old_str.replace(’,’, ’${dot}’) # 由于匹配到的引號僅為字符串申明,并不具有實際意義, # 需要把匹配時遇到的引號都去掉,只替換掉當前匹配組的引號 new_str = re.sub(data.group(’quote’), ’’, new_str) string = string.replace(old_str, new_str) sps = string.split(’,’) return map(lambda x: x.replace(’${dot}’, ’,’), sps) s = ’'2011,603','3510006998','F','5','5','0',''’print(list(split_by_dot_escape_quote(s)))
運行結(jié)果如下:
之前想的正則有些復雜,反而偏離了本意,還是對正則的認識不夠深。
以上這篇Python連接HDFS實現(xiàn)文件上傳下載及Pandas轉(zhuǎn)換文本文件到CSV操作就是小編分享給大家的全部內(nèi)容了,希望能給大家一個參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備