Python 批量讀取文件中指定字符的實現
1、背景
從指定的NLP生成的文件中讀取指定的字符。
2、待讀取文件
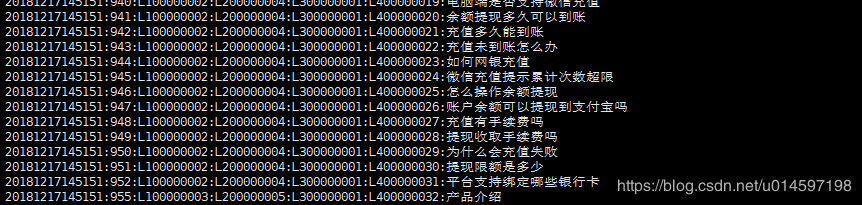
是以':'作為分隔符的數據,每一行以回車結束。此文件為XXX.train
3、讀取每一句中的漢字
...file_train = os.path.join(rootDir,'data/train/rg_train_'+modle_date+'_'+aiscene+'.train') with open(file_train, ’r’)as fp:textlist = fp.readlines()for text in textlist:if ':' in text:L4ID = text.split(':')[-2]Msg = text.split(':')[-1]if query_start == Msg.strip('n'):print('Msg is in train:',Msg)...
代碼中先獲取文件,然后讀取每一行,然后以':'作為分隔符。(-1代表倒數第一個,-2代表倒數第二個)
不管是txt文件還是xml文件還是其他的,都可以用這種方法來批量替換文件中字符串:
# -*- coding:utf-8 -*-__author__ = ’ShawDa’import globxmls = glob.glob(’xml_files/*.xml’)for one_xml in xmls: print(one_xml) f = open(one_xml, ’r+’, encoding=’utf-8’) all_the_lines = f.readlines() f.seek(0) f.truncate() for line in all_the_lines: line = line.replace(’dog’, ’pig’) line = line.replace(’cat’, ’bike’) f.write(line) f.close()
到此這篇關于Python 批量讀取文件中指定字符的實現的文章就介紹到這了,更多相關Python 批量讀取指定字符內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備