Python通過正則庫爬取淘寶商品信息代碼實(shí)例
使用正則庫爬取淘寶商品的商品信息,首先我們需要確定想要爬取的對(duì)象
我們在淘寶里搜索“python”,出來的結(jié)果
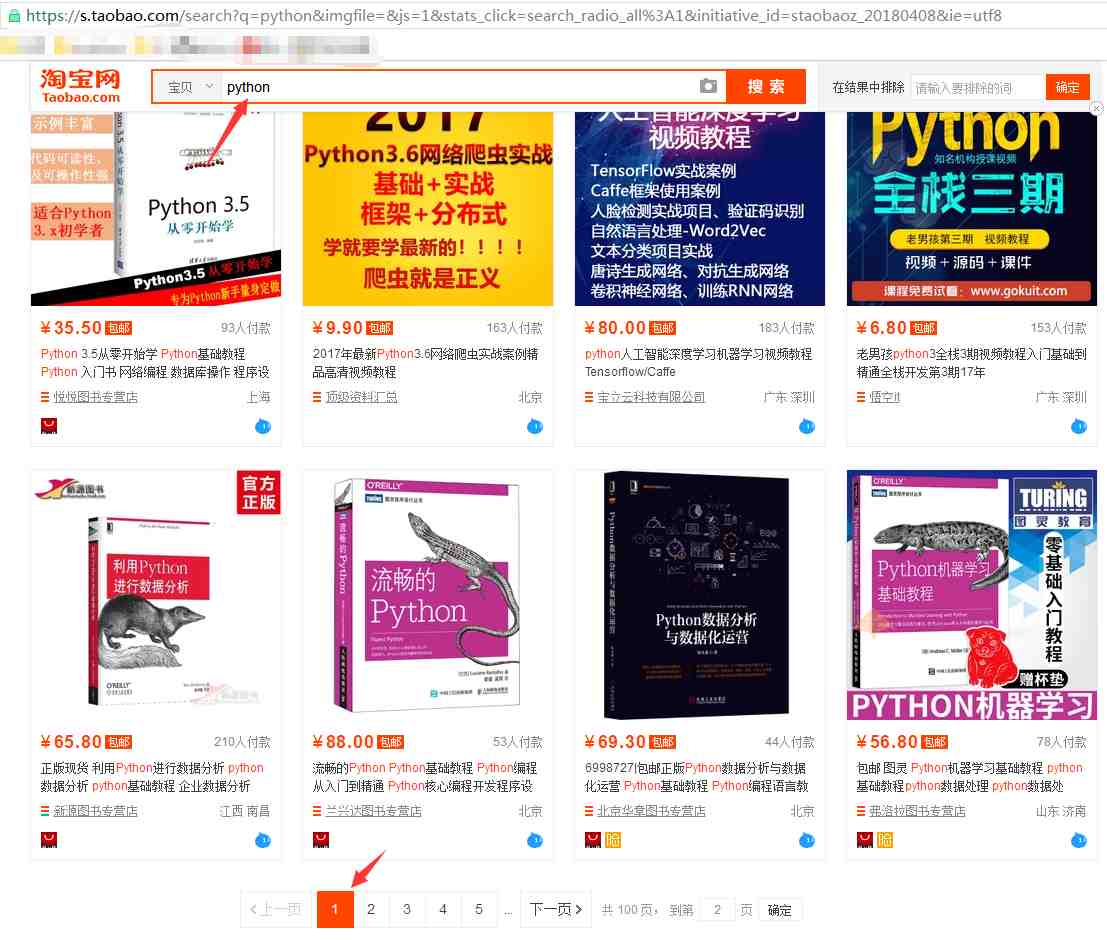
從url連接中可以得到搜索商品的關(guān)鍵字是“q=”,所以我們要用的起始url為:https://s.taobao.com/search?q=python
然后翻頁,經(jīng)過對(duì)比發(fā)現(xiàn),翻頁后,變化的關(guān)鍵字是s,每次翻頁,s便以44的倍數(shù)增長(可以數(shù)一下每頁顯示的商品數(shù)量,剛好是44)所以可以根據(jù)關(guān)鍵字“s=”,來設(shè)置爬取的深度(爬取多少頁)
右鍵查看源碼,商品名稱可能的關(guān)鍵字是“title”和“raw_title”,進(jìn)一步多看幾個(gè)商品的名稱,發(fā)現(xiàn)選取“raw_title”比較合適;商品價(jià)格自然就是“view_price”(通過比對(duì)淘寶商品展示頁面);所以商品名稱和商品價(jià)格分別是以'raw_title':'名稱'和'view_price':'價(jià)格',這樣的鍵/值對(duì)的形式展示的。
# coding:utf-8import requestsimport regoods = ’水杯’url = ’https://s.taobao.com/search?q=’ + goodsr = requests.get(url=url, timeout=10)html = r.texttlist = re.findall(r’'raw_title':'.*?'’, html) # 正則提取商品名稱plist = re.findall(r’'view_price':'[d.]*'’, html) # 正則提示商品價(jià)格print(tlist)print(plist)print(type(plist)) # 正則表達(dá)式提取出的商品名稱和商品價(jià)格都是以列表形式存儲(chǔ)數(shù)據(jù)的
利用for循環(huán),把每個(gè)商品的名稱和價(jià)格組成一個(gè)列表,然后把這寫列表再追加到一個(gè)大列表中:
goodlist = []for i in range(len(tlist)): title = eval(tlist[i].split(’:’)[1]) # eval()函數(shù)簡單說就是用于去掉字符串的引號(hào) price = eval(plist[i].split(’:’)[1]) goodlist.append([title, price]) # 把每個(gè)商品的名稱和價(jià)格組成一個(gè)小列表,然后把所有商品組成的列表追加到一個(gè)大列表中 print(goodlist)
大概的思路就是這樣的。
def get_html(url): '''獲取源碼html''' try: r = requests.get(url=url, timeout=10) r.encoding = r.apparent_encoding return r.text except: print('獲取失敗')def get_data(html, goodlist): '''使用re庫解析商品名稱和價(jià)格 tlist:商品名稱列表 plist:商品價(jià)格列表''' tlist = re.findall(r’'raw_title':'.*?'’, html) plist = re.findall(r’'view_price':'[d.]*'’, html) for i in range(len(tlist)): title = eval(tlist[i].split(’:’)[1]) # eval()函數(shù)簡單說就是用于去掉字符串的引號(hào) price = eval(plist[i].split(’:’)[1]) goodlist.append([title, price])def write_data(list, num): # with open(’E:/Crawler/case/taob2.txt’, ’a’) as data: # print(list, file=data) for i in range(num): # num控制把爬取到的商品寫進(jìn)多少到文本中 u = list[i] with open(’E:/Crawler/case/taob.txt’, ’a’) as data: print(u, file=data)def main(): goods = ’水杯’ depth = 3 # 定義爬取深度,即翻頁處理 start_url = ’https://s.taobao.com/search?q=’ + goods infoList = [] for i in range(depth): try: url = start_url + ’&s=’ + str(44 * i) # 因?yàn)樘詫氾@示每頁44個(gè)商品,第一頁i=0,一次遞增 html = get_html(url) get_data(html, infoList) except: continue write_data(infoList, len(infoList))if __name__ == ’__main__’: main()
以上就是本文的全部內(nèi)容,希望對(duì)大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. django queryset相加和篩選教程2. Java PreparedStatement用法詳解3. 使用AJAX(包含正則表達(dá)式)驗(yàn)證用戶登錄的步驟4. 利用ajax+php實(shí)現(xiàn)商品價(jià)格計(jì)算5. IDEA 2020.1.2 安裝教程附破解教程詳解6. JS圖片懶加載庫VueLazyLoad詳解7. idea設(shè)置提示不區(qū)分大小寫的方法8. Java利用TCP協(xié)議實(shí)現(xiàn)客戶端與服務(wù)器通信(附通信源碼)9. Spring如何集成ibatis項(xiàng)目并實(shí)現(xiàn)dao層基類封裝10. IntelliJ IDEA導(dǎo)出項(xiàng)目的方法
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備