Python爬蟲(chóng)實(shí)戰(zhàn)之使用Scrapy爬取豆瓣圖片
以莫妮卡·貝魯奇為例
1.首先我們?cè)诿钚羞M(jìn)入到我們要?jiǎng)?chuàng)建的目錄,輸入 scrapy startproject banciyuan 創(chuàng)建scrapy項(xiàng)目
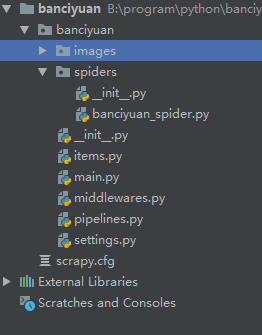
創(chuàng)建的項(xiàng)目結(jié)構(gòu)如下
2.為了方便使用pycharm執(zhí)行scrapy項(xiàng)目,新建main.py
from scrapy import cmdlinecmdline.execute('scrapy crawl banciyuan'.split())
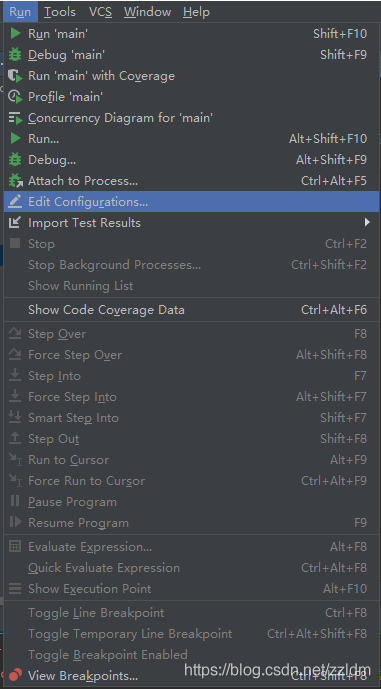
再edit configuration
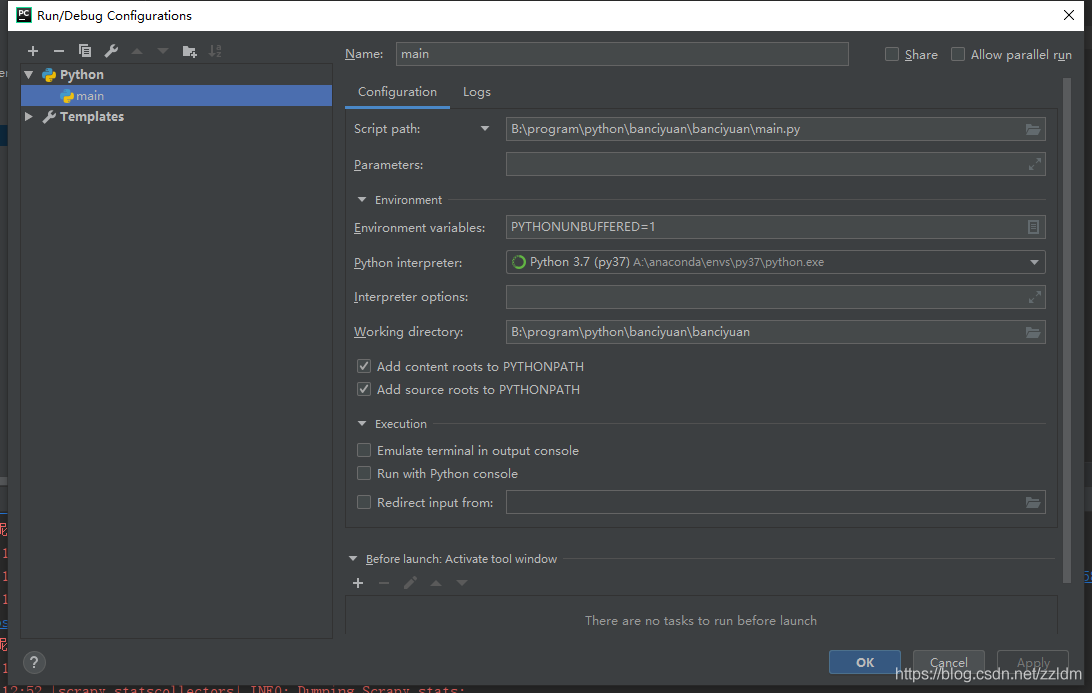
然后進(jìn)行如下設(shè)置,設(shè)置后之后就能通過(guò)運(yùn)行main.py運(yùn)行scrapy項(xiàng)目了
3.分析該HTML頁(yè)面,創(chuàng)建對(duì)應(yīng)spider
from scrapy import Spiderimport scrapyfrom banciyuan.items import BanciyuanItemclass BanciyuanSpider(Spider): name = ’banciyuan’ allowed_domains = [’movie.douban.com’] start_urls = ['https://movie.douban.com/celebrity/1025156/photos/'] url = 'https://movie.douban.com/celebrity/1025156/photos/' def parse(self, response):num = response.xpath(’//div[@class='paginator']/a[last()]/text()’).extract_first(’’)print(num)for i in range(int(num)): suffix = ’?type=C&start=’ + str(i * 30) + ’&sortby=like&size=a&subtype=a’ yield scrapy.Request(url=self.url + suffix, callback=self.get_page) def get_page(self, response):href_list = response.xpath(’//div[@class='article']//div[@class='cover']/a/@href’).extract()# print(href_list)for href in href_list: yield scrapy.Request(url=href, callback=self.get_info) def get_info(self, response):src = response.xpath( ’//div[@class='article']//div[@class='photo-show']//div[@class='photo-wp']/a[1]/img/@src’).extract_first(’’)title = response.xpath(’//div[@id='content']/h1/text()’).extract_first(’’)# print(response.body)item = BanciyuanItem()item[’title’] = titleitem[’src’] = [src]yield item
4.items.py
# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass BanciyuanItem(scrapy.Item): # define the fields for your item here like: src = scrapy.Field() title = scrapy.Field()
pipelines.py
# Define your item pipelines here## Don’t forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfacefrom itemadapter import ItemAdapterfrom scrapy.pipelines.images import ImagesPipelineimport scrapyclass BanciyuanPipeline(ImagesPipeline): def get_media_requests(self, item, info):yield scrapy.Request(url=item[’src’][0], meta={’item’: item}) def file_path(self, request, response=None, info=None, *, item=None):item = request.meta[’item’]image_name = item[’src’][0].split(’/’)[-1]# image_name.replace(’.webp’, ’.jpg’)path = ’%s/%s’ % (item[’title’].split(’ ’)[0], image_name)return path
settings.py
# Scrapy settings for banciyuan project## For simplicity, this file contains only settings considered important or# commonly used. You can find more settings consulting the documentation:## https://docs.scrapy.org/en/latest/topics/settings.html# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = ’banciyuan’SPIDER_MODULES = [’banciyuan.spiders’]NEWSPIDER_MODULE = ’banciyuan.spiders’# Crawl responsibly by identifying yourself (and your website) on the user-agentUSER_AGENT = {’User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36’}# Obey robots.txt rulesROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docs#DOWNLOAD_DELAY = 3# The download delay setting will honor only one of:#CONCURRENT_REQUESTS_PER_DOMAIN = 16#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)#TELNETCONSOLE_ENABLED = False# Override the default request headers:#DEFAULT_REQUEST_HEADERS = {# ’Accept’: ’text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,# ’Accept-Language’: ’en’,#}# Enable or disable spider middlewares# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html#SPIDER_MIDDLEWARES = {# ’banciyuan.middlewares.BanciyuanSpiderMiddleware’: 543,#}# Enable or disable downloader middlewares# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#DOWNLOADER_MIDDLEWARES = {# ’banciyuan.middlewares.BanciyuanDownloaderMiddleware’: 543,#}# Enable or disable extensions# See https://docs.scrapy.org/en/latest/topics/extensions.html#EXTENSIONS = {# ’scrapy.extensions.telnet.TelnetConsole’: None,#}# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { ’banciyuan.pipelines.BanciyuanPipeline’: 1,}IMAGES_STORE = ’./images’# Enable and configure the AutoThrottle extension (disabled by default)# See https://docs.scrapy.org/en/latest/topics/autothrottle.html#AUTOTHROTTLE_ENABLED = True# The initial download delay#AUTOTHROTTLE_START_DELAY = 5# The maximum download delay to be set in case of high latencies#AUTOTHROTTLE_MAX_DELAY = 60# The average number of requests Scrapy should be sending in parallel to# each remote server#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0# Enable showing throttling stats for every response received:#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings#HTTPCACHE_ENABLED = True#HTTPCACHE_EXPIRATION_SECS = 0#HTTPCACHE_DIR = ’httpcache’#HTTPCACHE_IGNORE_HTTP_CODES = []#HTTPCACHE_STORAGE = ’scrapy.extensions.httpcache.FilesystemCacheStorage’
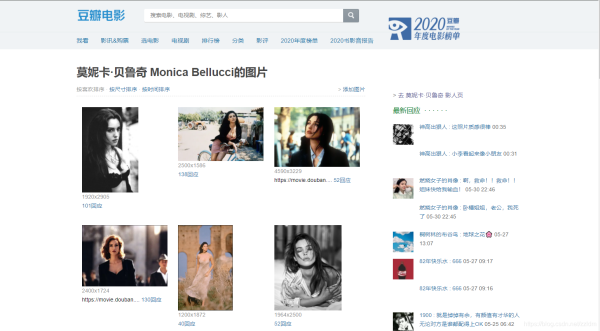
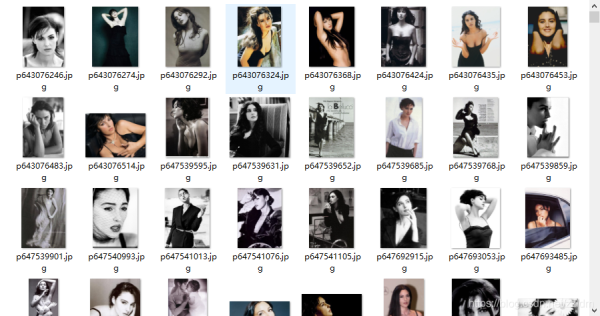
5.爬取結(jié)果
reference
源碼
到此這篇關(guān)于Python爬蟲(chóng)實(shí)戰(zhàn)之使用Scrapy爬取豆瓣圖片的文章就介紹到這了,更多相關(guān)Scrapy爬取豆瓣圖片內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. django queryset相加和篩選教程2. 使用AJAX(包含正則表達(dá)式)驗(yàn)證用戶登錄的步驟3. Java利用TCP協(xié)議實(shí)現(xiàn)客戶端與服務(wù)器通信(附通信源碼)4. IntelliJ IDEA導(dǎo)出項(xiàng)目的方法5. 利用ajax+php實(shí)現(xiàn)商品價(jià)格計(jì)算6. Java PreparedStatement用法詳解7. JS圖片懶加載庫(kù)VueLazyLoad詳解8. Spring如何集成ibatis項(xiàng)目并實(shí)現(xiàn)dao層基類封裝9. IDEA 2020.1.2 安裝教程附破解教程詳解10. idea設(shè)置提示不區(qū)分大小寫(xiě)的方法
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備