Python中scrapy下載保存圖片的示例
在日常爬蟲練習(xí)中,我們爬取到的數(shù)據(jù)需要進(jìn)行保存操作,在scrapy中我們可以使用ImagesPipeline這個(gè)類來進(jìn)行相關(guān)操作,這個(gè)類是scrapy已經(jīng)封裝好的了,我們直接拿來用即可。

在使用ImagesPipeline下載圖片數(shù)據(jù)時(shí),我們需要對(duì)其中的三個(gè)管道類方法進(jìn)行重寫,其中 — get_media_request 是對(duì)圖片地址發(fā)起請(qǐng)求
— file path 是返回圖片名稱
— item_completed 返回item,將其返回給下一個(gè)即將被執(zhí)行的管道類

那具體代碼是什么樣的呢,首先我們需要在pipelines.py文件中,導(dǎo)入ImagesPipeline類,然后重寫上述所說的3個(gè)方法:
from scrapy.pipelines.images import ImagesPipelineimport scrapyimport os class ImgsPipLine(ImagesPipeline): def get_media_requests(self, item, info):yield scrapy.Request(url = item[’img_src’],meta={’item’:item}) #返回圖片名稱即可 def file_path(self, request, response=None, info=None):item = request.meta[’item’]print(’########’,item)filePath = item[’img_name’]return filePath def item_completed(self, results, item, info):return item
方法定義好后,我們需要在settings.py配置文件中進(jìn)行設(shè)置,一個(gè)是指定圖片保存的位置IMAGES_STORE = ’D:ImgPro’,然后就是啟用“ImgsPipLine”管道,
ITEM_PIPELINES = { ’imgPro.pipelines.ImgsPipLine’: 300, #300代表優(yōu)先級(jí),數(shù)字越小優(yōu)先級(jí)越高}
設(shè)置完成后,我們運(yùn)行程序后就可以看到“D:ImgPro”下保存成功的圖片。
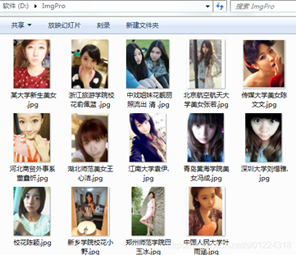
完整代碼如下:
spider文件代碼:
# -*- coding: utf-8 -*-import scrapyfrom imgPro.items import ImgproItem class ImgSpider(scrapy.Spider): name = ’img’ allowed_domains = [’www.521609.com’] start_urls = [’http://www.521609.com/daxuemeinv/’] def parse(self, response):#解析圖片地址和圖片名稱li_list = response.xpath(’//div[@class='index_img list_center']/ul/li’)for li in li_list: item = ImgproItem() item[’img_src’] = ’http://www.521609.com/’ + li.xpath(’./a[1]/img/@src’).extract_first() item[’img_name’] = li.xpath(’./a[1]/img/@alt’).extract_first() + ’.jpg’ # print(’***********’) # print(item) yield item
items.py文件
import scrapy class ImgproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() img_src = scrapy.Field() img_name = scrapy.Field()
pipelines.py文件
from scrapy.pipelines.images import ImagesPipelineimport scrapyimport osfrom imgPro.settings import IMAGES_STORE as IMGS class ImgsPipLine(ImagesPipeline): def get_media_requests(self, item, info):yield scrapy.Request(url = item[’img_src’],meta={’item’:item}) #返回圖片名稱即可 def file_path(self, request, response=None, info=None):item = request.meta[’item’]print(’########’,item)filePath = item[’img_name’]return filePath def item_completed(self, results, item, info):return item
settings.py文件
import randomBOT_NAME = ’imgPro’ SPIDER_MODULES = [’imgPro.spiders’]NEWSPIDER_MODULE = ’imgPro.spiders’ IMAGES_STORE = ’D:ImgPro’ #文件保存路徑LOG_LEVEL = 'WARNING'ROBOTSTXT_OBEY = False#設(shè)置user-agentUSER_AGENTS_LIST = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1','Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5','Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24' ]USER_AGENT = random.choice(USER_AGENTS_LIST)DEFAULT_REQUEST_HEADERS = { ’Accept’: ’text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’, ’Accept-Language’: ’en’, # ’User-Agent’:'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', ’User-Agent’:USER_AGENT} #啟動(dòng)pipeline管道ITEM_PIPELINES = { ’imgPro.pipelines.ImgsPipLine’: 300,}
以上即是使用ImagesPipeline下載保存圖片的方法,今天突生一個(gè)疑惑,爬蟲爬的好,真的是牢飯吃的飽嗎?還請(qǐng)各位大佬解答!更多相關(guān)Python scrapy下載保存內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 用python登錄帶弱圖片驗(yàn)證碼的網(wǎng)站2. Python基于Serializer實(shí)現(xiàn)字段驗(yàn)證及序列化3. 如何利用python的tkinter實(shí)現(xiàn)一個(gè)簡單的計(jì)算器4. Python中用xlwt制作表格實(shí)例講解5. python mysql 字段與關(guān)鍵字沖突的解決方式6. python實(shí)現(xiàn)xlwt xlrd 指定條件給excel行添加顏色7. 解決python便攜版無法直接運(yùn)行py文件的問題8. Python多線程操作之互斥鎖、遞歸鎖、信號(hào)量、事件實(shí)例詳解9. Python讀取二進(jìn)制文件代碼方法解析10. Python實(shí)現(xiàn)封裝打包自己寫的代碼,被python import
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備