文章列表
-
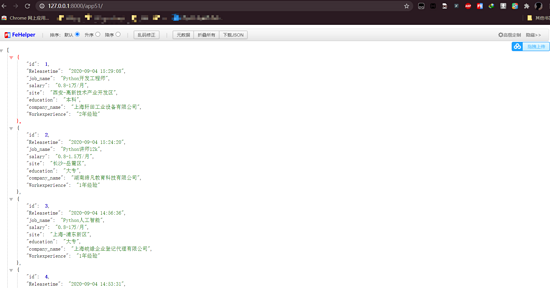
- Django-Scrapy生成后端json接口的方法示例
- 網(wǎng)上的關(guān)于django-scrapy的介紹比較少,該博客只在本人查資料的過(guò)程中學(xué)習(xí)的,如果不對(duì)之處,希望指出改正;以后的博客可能不會(huì)再出關(guān)于django相關(guān)的點(diǎn);人心太浮躁,個(gè)人深度不夠,只學(xué)習(xí)了一些皮毛,后面博客只求精,不求多;希望能堅(jiān)持下來(lái)。加油!學(xué)習(xí)點(diǎn): 實(shí)現(xiàn)效果 django與scrap...
- 日期:2024-05-27
- 瀏覽:156
- 標(biāo)簽: JavaScript
-
- Django結(jié)合使用Scrapy爬取數(shù)據(jù)入庫(kù)的方法示例
- 在django項(xiàng)目根目錄位置創(chuàng)建scrapy項(xiàng)目,django_12是django項(xiàng)目,ABCkg是scrapy爬蟲(chóng)項(xiàng)目,app1是django的子應(yīng)用2.在Scrapy的settings.py中加入以下代碼import osimport syssys.path.append(os.path.dir...
- 日期:2024-09-11
- 瀏覽:8
- 標(biāo)簽: Django

-
- Python中scrapy下載保存圖片的示例
- 在日常爬蟲(chóng)練習(xí)中,我們爬取到的數(shù)據(jù)需要進(jìn)行保存操作,在scrapy中我們可以使用ImagesPipeline這個(gè)類(lèi)來(lái)進(jìn)行相關(guān)操作,這個(gè)類(lèi)是scrapy已經(jīng)封裝好的了,我們直接拿來(lái)用即可。 在使用ImagesPipeline下載圖片數(shù)...
- 日期:2022-06-14
- 瀏覽:57
-
- Python Scrapy框架:通用爬蟲(chóng)之CrawlSpider用法簡(jiǎn)單示例
- 本文實(shí)例講述了Python Scrapy框架:通用爬蟲(chóng)之CrawlSpider用法。分享給大家供大家參考,具體如下:步驟01: 創(chuàng)建爬蟲(chóng)項(xiàng)目scrapy startproject quotes步驟02: 創(chuàng)建爬蟲(chóng)模版scrapy genspider -t quotes quotes.toscrape...
- 日期:2022-07-30
- 瀏覽:6
-
- python實(shí)現(xiàn)scrapy爬蟲(chóng)每天定時(shí)抓取數(shù)據(jù)的示例代碼
- 1. 前言。1.1. 需求背景。 每天抓取的是同一份商品的數(shù)據(jù),用來(lái)做趨勢(shì)分析。 要求每天都需要抓一份,也僅限抓取一份數(shù)據(jù)。 但是整個(gè)爬取數(shù)據(jù)的過(guò)程在時(shí)間上并不確定,受本地網(wǎng)絡(luò),代理速度,抓取數(shù)據(jù)量有關(guān),一般情況下在20小時(shí)左右,極少情況下會(huì)超過(guò)24小時(shí)。1.2. 實(shí)現(xiàn)功能。通過(guò)以下三步,保證...
- 日期:2022-06-29
- 瀏覽:4
-
- 如何在django中運(yùn)行scrapy框架
- 1.新建一個(gè)django項(xiàng)目,2.前端展示一個(gè)按鈕<form action='/start/' method='POST'> {% csrf_token %} <input type='submit' value='啟動(dòng)爬蟲(chóng)'></form>3.在dj...
- 日期:2024-10-09
- 瀏覽:4
- 標(biāo)簽: Django
-
- Python爬蟲(chóng)實(shí)例——scrapy框架爬取拉勾網(wǎng)招聘信息
- 本文實(shí)例為爬取拉勾網(wǎng)上的python相關(guān)的職位信息, 這些信息在職位詳情頁(yè)上, 如職位名, 薪資, 公司名等等.分析思路分析查詢(xún)結(jié)果頁(yè)在拉勾網(wǎng)搜索框中搜索’python’關(guān)鍵字, 在瀏覽器地址欄可以看到搜索結(jié)果頁(yè)的url為: ’https://www.lagou.com/jobs/list_pyth...
- 日期:2022-07-17
- 瀏覽:154
-
- 詳解Python的爬蟲(chóng)框架 Scrapy
- 網(wǎng)絡(luò)爬蟲(chóng),是在網(wǎng)上進(jìn)行數(shù)據(jù)抓取的程序,使用它能夠抓取特定網(wǎng)頁(yè)的HTML數(shù)據(jù)。雖然我們利用一些庫(kù)開(kāi)發(fā)一個(gè)爬蟲(chóng)程序,但是使用框架可以大大提高效率,縮短開(kāi)發(fā)時(shí)間。Scrapy是一個(gè)使用Python編寫(xiě)的,輕量級(jí)的,簡(jiǎn)單輕巧,并且使用起來(lái)非常的方便。一、概述下圖顯示了Scrapy的大體架構(gòu),其中包含了它的主...
- 日期:2022-07-15
- 瀏覽:4

-
- 簡(jiǎn)述python Scrapy框架
- 一、Scrapy框架簡(jiǎn)介Scrapy是用純Python實(shí)現(xiàn)一個(gè)為了爬取網(wǎng)站數(shù)據(jù),提取結(jié)構(gòu)性數(shù)據(jù)而編寫(xiě)的應(yīng)用框架,用途非常廣泛。利用框架,用戶(hù)只需要定制開(kāi)發(fā)幾個(gè)模塊就可以輕松的實(shí)現(xiàn)一個(gè)爬蟲(chóng),用來(lái)抓取網(wǎng)頁(yè)內(nèi)容以及各種圖片,非常的方便。它使用Twisted這個(gè)異步網(wǎng)絡(luò)庫(kù)來(lái)處理網(wǎng)絡(luò)通訊,架構(gòu)清晰,并且包含了...
- 日期:2022-07-13
- 瀏覽:3

-
- Python爬蟲(chóng)Scrapy框架CrawlSpider原理及使用案例
- 提問(wèn):如果想要通過(guò)爬蟲(chóng)程序去爬取”糗百“全站數(shù)據(jù)新聞數(shù)據(jù)的話(huà),有幾種實(shí)現(xiàn)方法?方法一:基于Scrapy框架中的Spider的遞歸爬去進(jìn)行實(shí)現(xiàn)的(Request模塊回調(diào))方法二:基于CrawlSpider的自動(dòng)爬去進(jìn)行實(shí)現(xiàn)(更加簡(jiǎn)潔和高效)一、簡(jiǎn)單介紹CrawlSpiderCrawlSpider其實(shí)是...
- 日期:2022-07-04
- 瀏覽:4
排行榜
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備