Mysql在大型網(wǎng)站的應(yīng)用架構(gòu)演變
本文主要描述在網(wǎng)站的不同的并發(fā)訪問(wèn)量級(jí)下,Mysql架構(gòu)的演變
可擴(kuò)展性架構(gòu)的可擴(kuò)展性往往和并發(fā)是息息相關(guān),沒(méi)有并發(fā)的增長(zhǎng),也就沒(méi)有必要做高可擴(kuò)展性的架構(gòu),這里對(duì)可擴(kuò)展性進(jìn)行簡(jiǎn)單介紹一下,常用的擴(kuò)展手段有以下兩種
Scale-up : 縱向擴(kuò)展,通過(guò)替換為更好的機(jī)器和資源來(lái)實(shí)現(xiàn)伸縮,提升服務(wù)能力
Scale-out : 橫向擴(kuò)展, 通過(guò)加節(jié)點(diǎn)(機(jī)器)來(lái)實(shí)現(xiàn)伸縮,提升服務(wù)能力
對(duì)于互聯(lián)網(wǎng)的高并發(fā)應(yīng)用來(lái)說(shuō),無(wú)疑Scale out才是出路,通過(guò)縱向的買更高端的機(jī)器一直是我們所避諱的問(wèn)題,也不是長(zhǎng)久之計(jì),在scale out的理論下,可擴(kuò)展性的理想狀態(tài)是什么?
可擴(kuò)展性的理想狀態(tài)一個(gè)服務(wù),當(dāng)面臨更高的并發(fā)的時(shí)候,能夠通過(guò)簡(jiǎn)單增加機(jī)器來(lái)提升服務(wù)支撐的并發(fā)度,且增加機(jī)器過(guò)程中對(duì)線上服務(wù)無(wú)影響(no down time),這就是可擴(kuò)展性的理想狀態(tài)!
架構(gòu)的演變V1.0 簡(jiǎn)單網(wǎng)站架構(gòu)一個(gè)簡(jiǎn)單的小型網(wǎng)站或者應(yīng)用背后的架構(gòu)可以非常簡(jiǎn)單, 數(shù)據(jù)存儲(chǔ)只需要一個(gè)mysql instance就能滿足數(shù)據(jù)讀取和寫入需求(這里忽略掉了數(shù)據(jù)備份的實(shí)例),處于這個(gè)時(shí)間段的網(wǎng)站,一般會(huì)把所有的信息存到一個(gè)database instance里面。
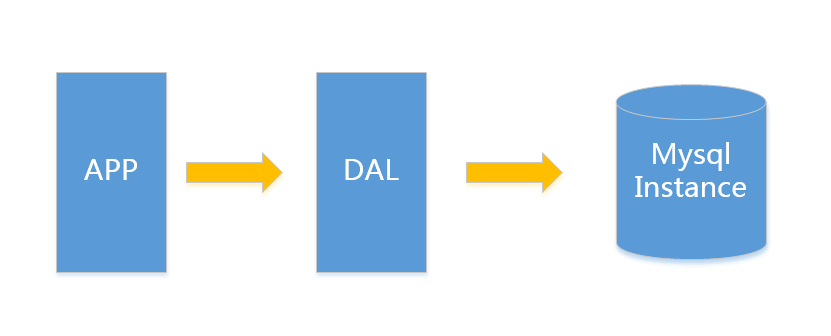
在這樣的架構(gòu)下,我們來(lái)看看數(shù)據(jù)存儲(chǔ)的瓶頸是什么?
1.數(shù)據(jù)量的總大小 一個(gè)機(jī)器放不下時(shí)
2.數(shù)據(jù)的索引(B+ Tree)一個(gè)機(jī)器的內(nèi)存放不下時(shí)
3.訪問(wèn)量(讀寫混合)一個(gè)實(shí)例不能承受
只有當(dāng)以上3件事情任何一件或多件滿足時(shí),我們才需要考慮往下一級(jí)演變。 從此我們可以看出,事實(shí)上對(duì)于很多小公司小應(yīng)用,這種架構(gòu)已經(jīng)足夠滿足他們的需求了,初期數(shù)據(jù)量的準(zhǔn)確評(píng)估是杜絕過(guò)度設(shè)計(jì)很重要的一環(huán),畢竟沒(méi)有人愿意為不可能發(fā)生的事情而浪費(fèi)自己的經(jīng)歷。
這里簡(jiǎn)單舉個(gè)我的例子,對(duì)于用戶信息這類表 (3個(gè)索引),16G內(nèi)存能放下大概2000W行數(shù)據(jù)的索引,簡(jiǎn)單的讀和寫混合訪問(wèn)量3000/s左右沒(méi)有問(wèn)題,你的應(yīng)用場(chǎng)景是否
V2.0 垂直拆分一般當(dāng)V1.0 遇到瓶頸時(shí),首先最簡(jiǎn)便的拆分方法就是垂直拆分,何謂垂直?就是從業(yè)務(wù)角度來(lái)看,將關(guān)聯(lián)性不強(qiáng)的數(shù)據(jù)拆分到不同的instance上,從而達(dá)到消除瓶頸的目標(biāo)。以圖中的為例,將用戶信息數(shù)據(jù),和業(yè)務(wù)數(shù)據(jù)拆分到不同的三個(gè)實(shí)例上。對(duì)于重復(fù)讀類型比較多的場(chǎng)景,我們還可以加一層cache,來(lái)減少對(duì)DB的壓力。

在這樣的架構(gòu)下,我們來(lái)看看數(shù)據(jù)存儲(chǔ)的瓶頸是什么?
1.單實(shí)例單業(yè)務(wù) 依然存在V1.0所述瓶頸
遇到瓶頸時(shí)可以考慮往本文更高V版本升級(jí), 若是讀請(qǐng)求導(dǎo)致達(dá)到性能瓶頸可以考慮往V3.0升級(jí), 其他瓶頸考慮往V4.0升級(jí)
V3.0 主從架構(gòu)此類架構(gòu)主要解決V2.0架構(gòu)下的讀問(wèn)題,通過(guò)給Instance掛數(shù)據(jù)實(shí)時(shí)備份的思路來(lái)遷移讀取的壓力,在Mysql的場(chǎng)景下就是通過(guò)主從結(jié)構(gòu),主庫(kù)抗寫壓力,通過(guò)從庫(kù)來(lái)分擔(dān)讀壓力,對(duì)于寫少讀多的應(yīng)用,V3.0主從架構(gòu)完全能夠勝任
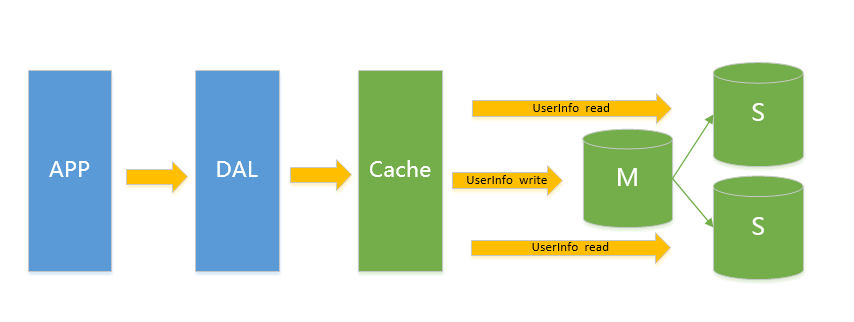
在這樣的架構(gòu)下,我們來(lái)看看數(shù)據(jù)存儲(chǔ)的瓶頸是什么?
1.寫入量主庫(kù)不能承受
V4.0 水平拆分對(duì)于V2.0 V3.0方案遇到瓶頸時(shí),都可以通過(guò)水平拆分來(lái)解決,水平拆分和垂直拆分有較大區(qū)別,垂直拆分拆完的結(jié)果,在一個(gè)實(shí)例上是擁有全量數(shù)據(jù)的,而水平拆分之后,任何實(shí)例都只有全量的1/n的數(shù)據(jù),以下圖Userinfo的拆分為例,將userinfo拆分為3個(gè)cluster,每個(gè)cluster持有總量的1/3數(shù)據(jù),3個(gè)cluster數(shù)據(jù)的總和等于一份完整數(shù)據(jù)(注:這里不再叫單個(gè)實(shí)例 而是叫一個(gè)cluster 代表包含主從的一個(gè)小mysql集群)
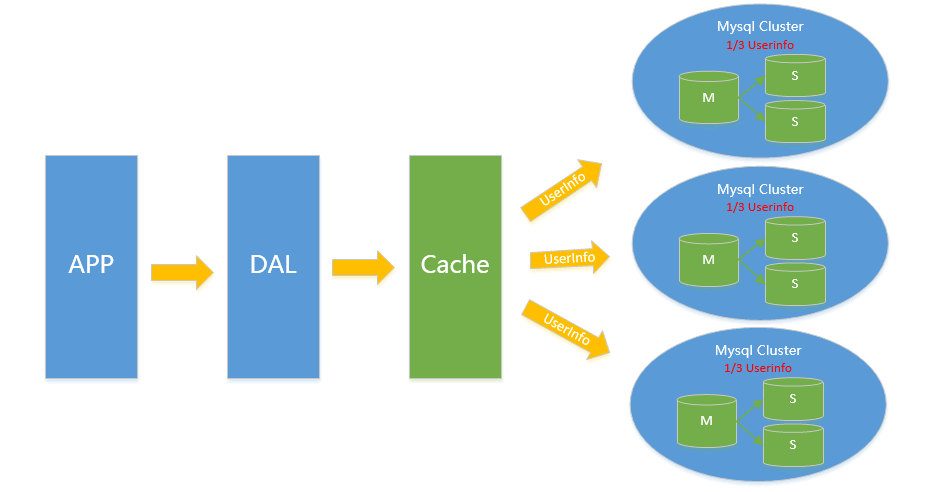
sharding key按連續(xù)區(qū)間段路由,一般用在有嚴(yán)格自增ID需求的場(chǎng)景上,如Userid, Userid Range的小例子:以u(píng)serid 3000W 為Range進(jìn)行拆分 1號(hào)cluster userid 1-3000W 2號(hào)cluster userid 3001W-6000W
2.List拆分List拆分與Range拆分思路一樣,都是通過(guò)給不同的sharding key來(lái)路由到不同的cluster,但是具體方法有些不同,List主要用來(lái)做sharding key不是連續(xù)區(qū)間的序列落到一個(gè)cluster的情況,如以下場(chǎng)景:假定有20個(gè)音像店,分布在4個(gè)有經(jīng)銷權(quán)的地區(qū),如下表所示:
地區(qū)
商店ID 號(hào)
北區(qū)
3, 5, 6, 9, 17
東區(qū)
1, 2, 10, 11, 19, 20
西區(qū)
4, 12, 13, 14, 18
中心區(qū)
7, 8, 15, 16
相關(guān)文章:
1. MySQL基本調(diào)度策略淺析2. Access數(shù)據(jù)庫(kù)日常維護(hù)方法(優(yōu)化)3. 巧用SQL語(yǔ)言在ACCESS數(shù)據(jù)庫(kù)中批量替換內(nèi)容4. mybatis 為什么千萬(wàn)不要使用 where 1=15. Microsoft Office Access設(shè)置小數(shù)位數(shù)的方法6. 如何實(shí)現(xiàn)MySQL數(shù)據(jù)庫(kù)的備份與恢復(fù)7. 數(shù)據(jù)庫(kù)相關(guān)的幾個(gè)技能:ACCESS轉(zhuǎn)SQL8. DB2 常用命令小結(jié)9. Mysql入門系列:安排預(yù)防性的維護(hù)MYSQL數(shù)據(jù)庫(kù)服務(wù)器10. SQL Server靜態(tài)頁(yè)面導(dǎo)出技術(shù)4

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備